Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the Repeat Curse. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model’s growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present CoTA, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code will be made available.
@inproceedings{zhao2026context,title={Context Tokens are Anchors: Understanding the Repetition Curse in Diffusion {MLLM}s from an Information Flow Perspective},author={Zhao, Qiyan and Zhang, Xiaofeng and Chang, Shuochen and Chen, Qianyu and Yuan, Xiaosong and Chen, Xuhang and Liu, Luoqi and Zhang, Jiajun and Zhang, Xu-Yao and Wang, Da-Han},booktitle={International Conference on Learning Representations (ICLR)},address={Rio de Janeiro, Brazil},year={2026},}
2025
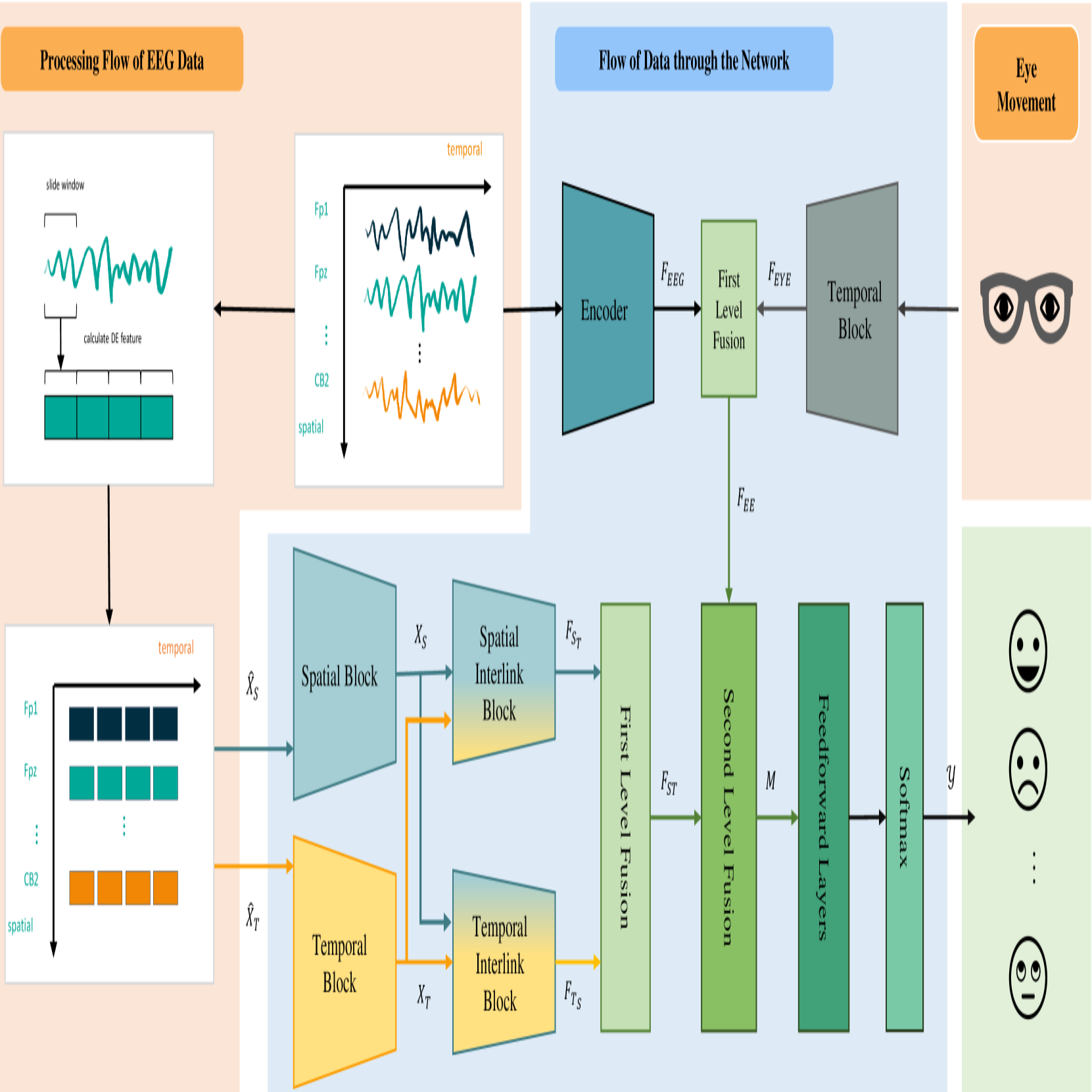
Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition
Emotion recognition based on Electroencephalography (EEG) has gained significant attention and diversified development in fields such as neural signal processing and affective computing. However, the unique brain anatomy of individuals leads to non-negligible natural differences in EEG signals across subjects, posing challenges for cross-subject emotion recognition. While recent studies have attempted to address these issues, they still face limitations in practical effectiveness and model framework unity. Current methods often struggle to capture the complex spatial-temporal dynamics of EEG signals and fail to effectively integrate multimodal information, resulting in suboptimal performance and limited generalizability across subjects. To overcome these limitations, we develop a Pre-trained model based Multimodal Mood Reader for cross-subject emotion recognition that utilizes masked brain signal modeling and interlinked spatial-temporal attention mechanism. The model learns universal latent representations of EEG signals through pre-training on large scale dataset, and employs Interlinked spatial-temporal attention mechanism to process Differential Entropy (DE) features extracted from EEG data. Subsequently, a multi-level fusion layer is proposed to integrate the discriminative features, maximizing the advantages of features across different dimensions and modalities. Extensive experiments on public datasets demonstrate Mood Reader’s superior performance in cross-subject emotion recognition tasks, outperforming state-of-the-art methods. Additionally, the model is dissected from attention perspective, providing qualitative analysis of emotion-related brain areas, offering valuable insights for affective research in neural signal processing.
@inproceedings{dong2025multi-modal,title={Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition},author={Dong, Yihang and Chen, Xuhang and Shen, Yanyan and Ng, Michael Kwok-Po and Qian, Tao and Wang, Shuqiang},year={2025},booktitle={Neural Computing for Advanced Applications (NCAA)},publisher={Springer},address={Guilin, China},pages={178--192},doi={10.1007/978-981-97-7007-6_13},}
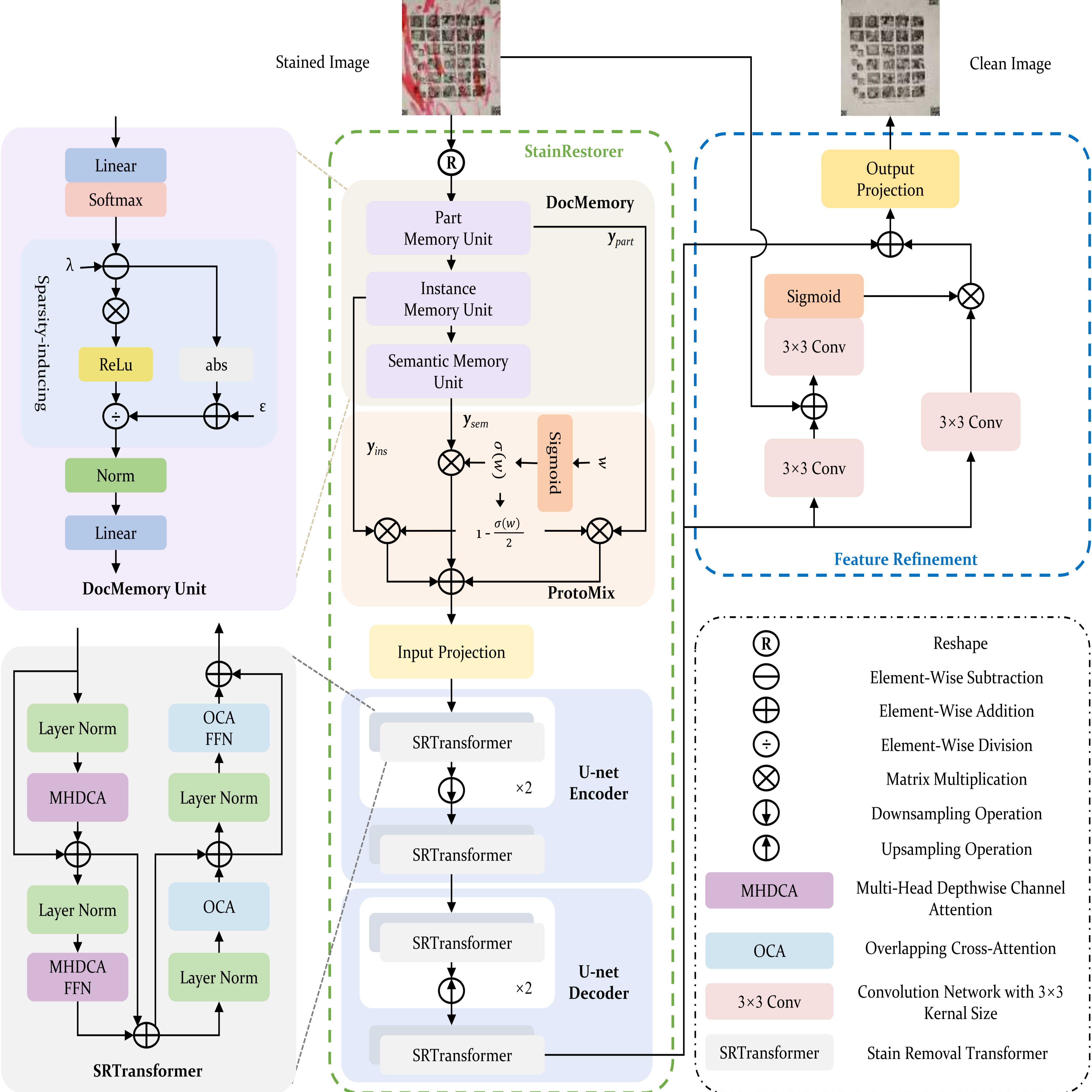
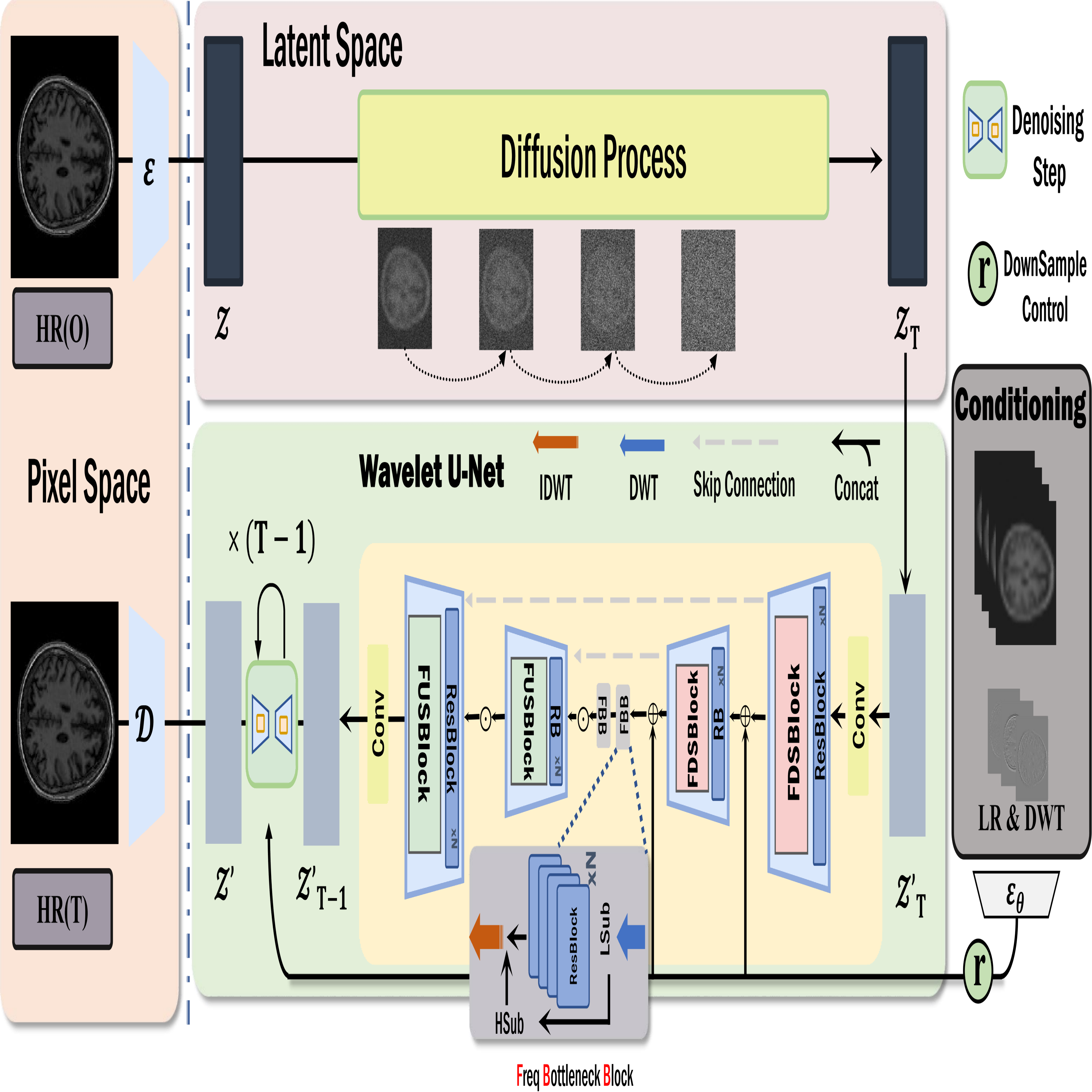
Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution (2145\times2245) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer’s superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc_Mark and StainDoc_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
@inproceedings{li2025high-fidelity,title={High-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer},author={Li, Mingxian and Sun, Hao and Lei, Yingtie and Zhang, Xiaofeng and Dong, Yihang and Zhou, Yilin and Li, Zimeng and Chen, Xuhang},year={2025},booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},publisher={IEEE},address={Tucson, AZ, USA},pages={7614--7624},doi={10.1109/WACV61041.2025.00740},}
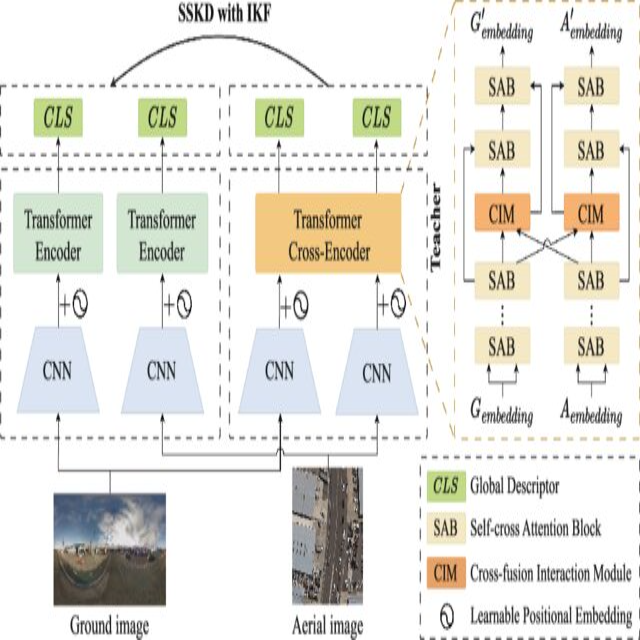
Cross-View Geo-Localization via Learning Correspondence Semantic Similarity Knowledge
Cross-view geo-localization aims at retrieving and estimating accurate geographic locations from ground images in a geo-tagged aerial image database. Existing approaches focus on two independent two-branch models to learn fine-grained representations of perspectives, neglecting to learn more discriminative representations through interactions. In this paper, we propose the GeoSSK method, which adapts the learning process of the model by learning local semantic similarity information between aerial and ground pairs via a new interaction module. We then transfer the semantic similarity knowledge learned during the interaction process to the student model through knowledge distillation. Specifically, we design a Cross-fusion Interaction Module (CIM) based on cross-attention, which learns local semantic similarity information between perspectives to adjust the learning of the model. Meanwhile, considering the presence of visual distractions in complex environments, we adjust the degree of interaction between perspectives by the Contribution Factor (CF) of the local representation to the global representation. In addition, we introduce Semantic Similarity Knowledge Distillation (SSKD) between teachers and students for cross-view geo-localization. The interaction learning model serves as the teacher, transferring its semantic similarity knowledge to the student. At the same time, we designed an Incorrect Knowledge Filter (IKF) to filter incorrect knowledge of teachers. Experimental results demonstrate the effectiveness and competitive performance of GeoSSK.
@inproceedings{chen2025cross-view,title={Cross-View Geo-Localization via Learning Correspondence Semantic Similarity Knowledge},author={Chen, Guanli and Huang, Guoheng and Yuan, Xiaochen and Chen, Xuhang and Zhong, Guo and Pun, Chi-Man},year={2025},booktitle={International Conference on Multimedia Modeling (MMM)},publisher={Springer},address={Nara, Japan},pages={220--233},doi={10.1007/978-981-96-2054-8_17},}
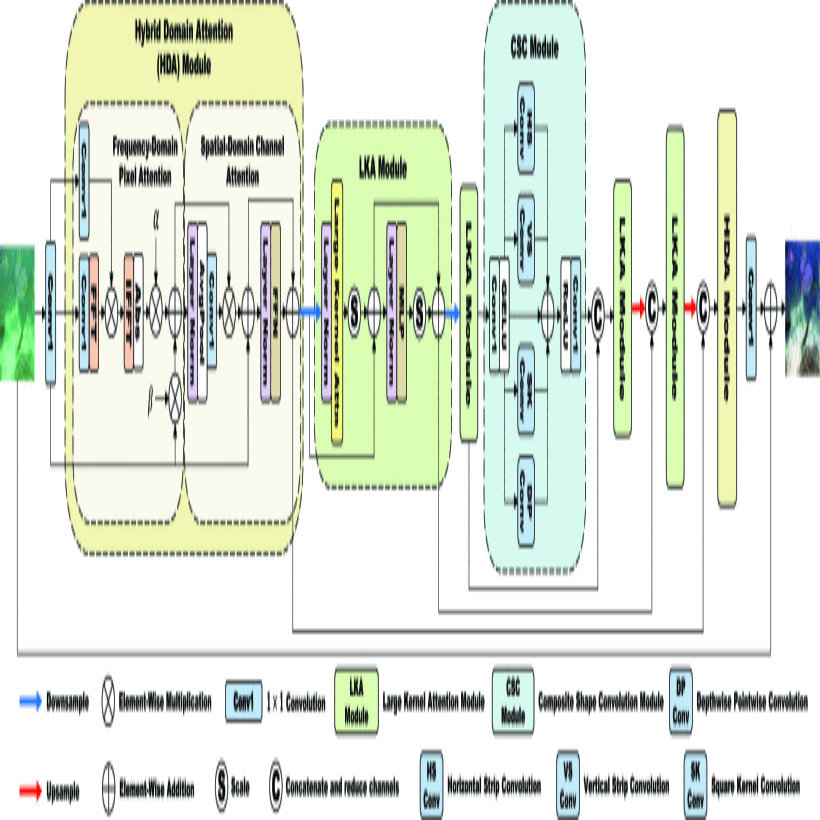
Underwater Image Restoration (UIR) remains a challenging task in computer vision due to the complex degradation of images in underwater environments. While recent approaches have leveraged various deep learning techniques, including Transformers and complex, parameter-heavy models to achieve significant improvements in restoration effects, we demonstrate that pure CNN architectures with lightweight parameters can achieve comparable results. In this paper, we introduce UIR-PolyKernel, a novel method for underwater image restoration that leverages Polymorphic Large Kernel CNNs. Our approach uniquely combines large kernel convolutions of diverse sizes and shapes to effectively capture long-range dependencies within underwater imagery. Additionally, we introduce a Hybrid Domain Attention module that integrates frequency and spatial domain attention mechanisms to enhance feature importance. By leveraging the frequency domain, we can capture hidden features that may not be perceptible to humans but are crucial for identifying patterns in both underwater and on-air images. This approach enhances the generalization and robustness of our UIR model. Extensive experiments on benchmark datasets demonstrate that UIR-PolyKernel achieves state-of-the-art performance in underwater image restoration tasks, both quantitatively and qualitatively. Our results show that well-designed pure CNN architectures can effectively compete with more complex models, offering a balance between performance and computational efficiency. This work provides new insights into the potential of CNN-based approaches for challenging image restoration tasks in underwater environments. The code is available at https://github.com/CXH-Research/UIR-PolyKernel.
@inproceedings{guo2025underwater1,title={Underwater Image Restoration via Polymorphic Large Kernel CNNs},author={Guo, Xiaojiao and Dong, Yihang and Chen, Xuhang and Chen, Weiwen and Li, Zimeng and Zheng, Fuchen and Pun, Chi-Man},year={2025},booktitle={Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},publisher={IEEE},address={Hyderabad, India},pages={1--5},doi={10.1109/ICASSP49660.2025.10890803},}
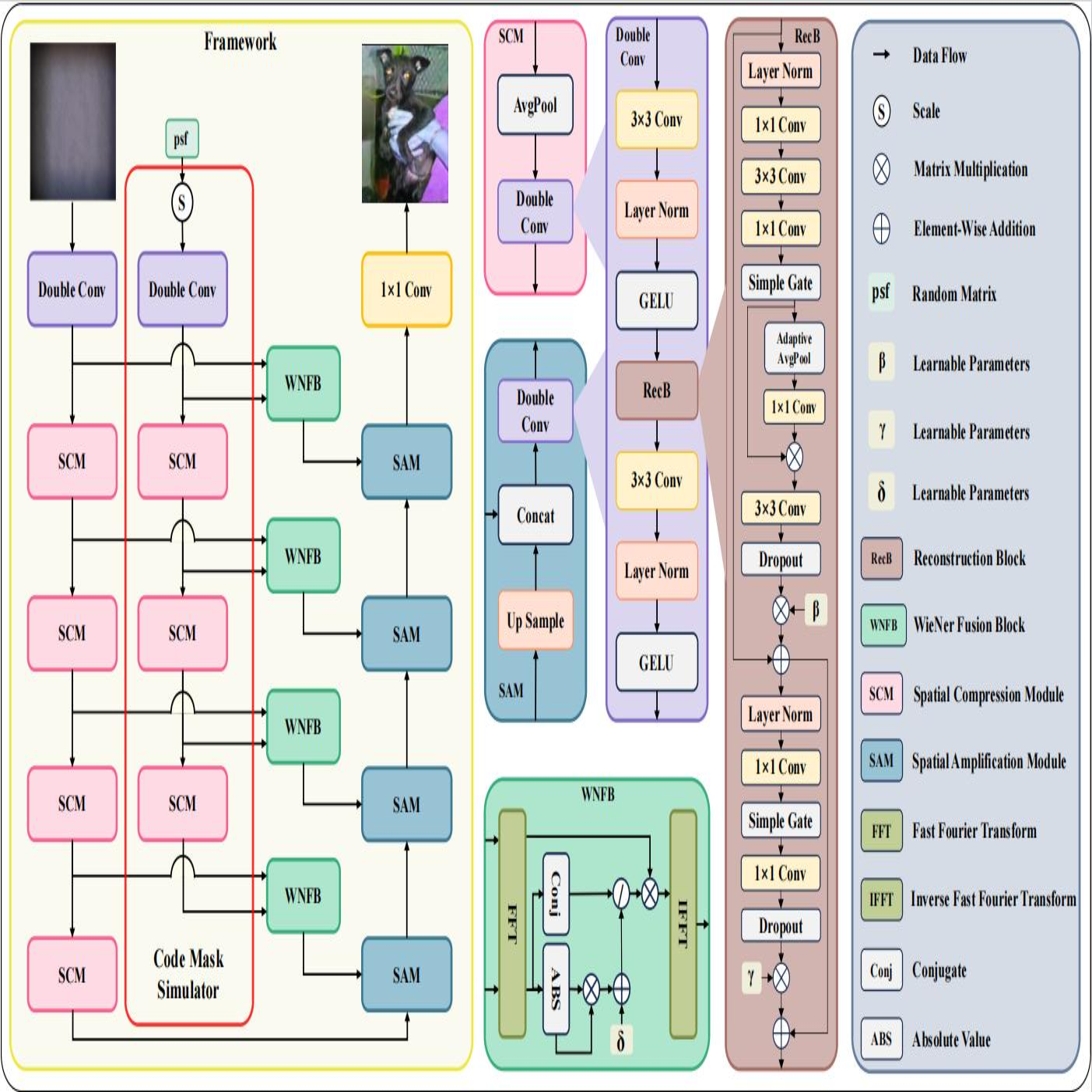
Lensless imaging stands out as a promising alternative to conventional lens-based systems, particularly in scenarios demanding ultracompact form factors and cost-effective architectures. However, such systems are fundamentally governed by the Point Spread Function (PSF), which dictates how a point source contributes to the final captured signal. Traditional lensless techniques often require explicit calibrations and extensive pre-processing, relying on static or approximate PSF models. These rigid strategies can result in limited adaptability to real-world challenges, including noise, system imperfections, and dynamic scene variations, thus impeding high-fidelity reconstruction. In this paper, we propose LensNet, an end-to-end deep learning framework that integrates spatial-domain and frequency-domain representations in a unified pipeline. Central to our approach is a learnable Coded Mask Simulator (CMS) that enables dynamic, data-driven estimation of the PSF during training, effectively mitigating the shortcomings of fixed or sparsely calibrated kernels. By embedding a Wiener filtering component, LensNet refines global structure and restores fine-scale details, thus alleviating the dependency on multiple handcrafted pre-processing steps. Extensive experiments demonstrate LensNet’s robust performance and superior reconstruction quality compared to state-of-the-art methods, particularly in preserving high-frequency details and attenuating noise. The proposed framework establishes a novel convergence between physics-based modeling and data-driven learning, paving the way for more accurate, flexible, and practical lensless imaging solutions for applications ranging from miniature sensors to medical diagnostics. The link of code is https://github.com/baijiesong/Lensnet.
@inproceedings{bai2025lensnet,title={LensNet: An End-to-End Learning Framework for Empirical Point Spread Function Modeling and Lensless Imaging Reconstruction},author={Bai, Jiesong and Yin, Yuhao and Dong, Yihang and Zhang, Xiaofeng and Pun, Chi-Man and Chen, Xuhang},year={2025},booktitle={Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI)},publisher={International Joint Conferences on Artificial Intelligence Organization},address={Montreal, Canada},pages={684--692},doi={10.24963/ijcai.2025/77},}
Code Retrieval with Mixture of Experts Prototype Learning Based on Classification
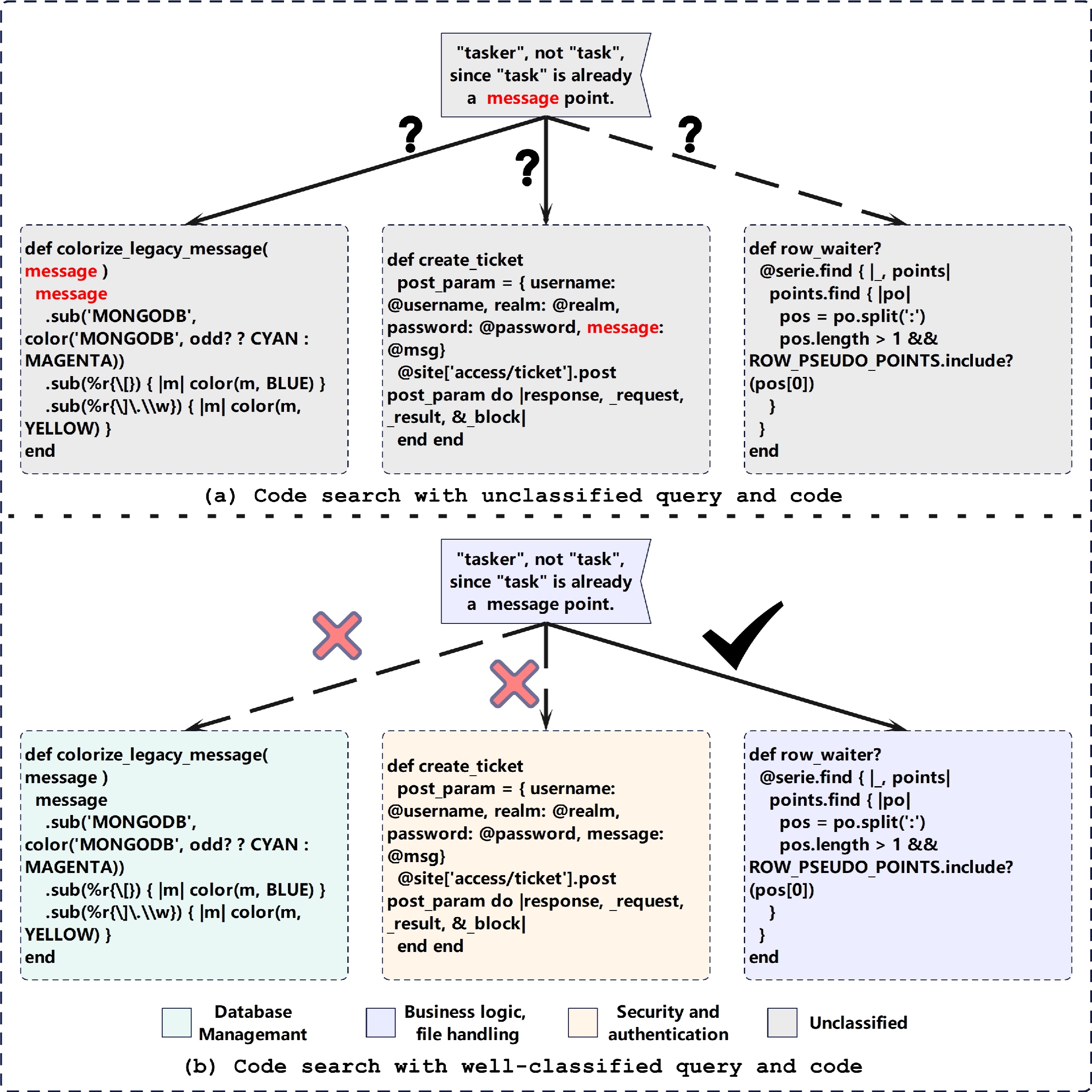
The semantic connection between code and queries is crucial for code retrieval, but many human-written queries fail to accurately capture the code’s core intent, leading to ambiguity. This ambiguity complicates the code search process, as the queries do not provide a clear overview of the code’s purpose. Our analysis reveals that while ambiguous queries may not precisely summarize the intent of the code, they often share the same general topics as the corresponding code. In light of this discovery, we propose Code Retrieval with Mixture of Experts Prototype Learning Based on Classification (CRME), a novel approach that combines classification for prototype-based representation learning and result ensembling. CRME utilizes specialized pre-trained models focused on the specific domains of ambiguous queries. It consists of two key components: Multiple Classification Prototype and Representation Learning with a Prototype-based Multi-model Contrastive (PMC) Loss during training, and Multi-Prototype Mixture of Experts Integration (MP-MoE) module for fine-grained ensemble inference. Our method can effectively address the issue of query ambiguity and improves search precision. Experimental results on the CodeSearchNet dataset, covering six sub-datasets, show that CRME outperforms existing methods, achieving an average MRR score of 81.4%. When applied to pre-trained models like CodeBERT, GraphCodeBERT, UniXcoder and CodeT5+, CRME can effectively boosts their performances.
@inproceedings{ling2025code,title={Code Retrieval with Mixture of Experts Prototype Learning Based on Classification},author={Ling, Feng and Huang, Guoheng and Wang, Jingchao and Yuan, Xiaochen and Chen, Xuhang and Zhang, Xueyong and Zhang, Fanlong and Pun, Chi-Man},year={2025},booktitle={Proceedings of the International Conference on Internetware (Internetware)},publisher={ACM},address={Trondheim, Norway},pages={47--58},doi={10.1145/3755881.3755893},}
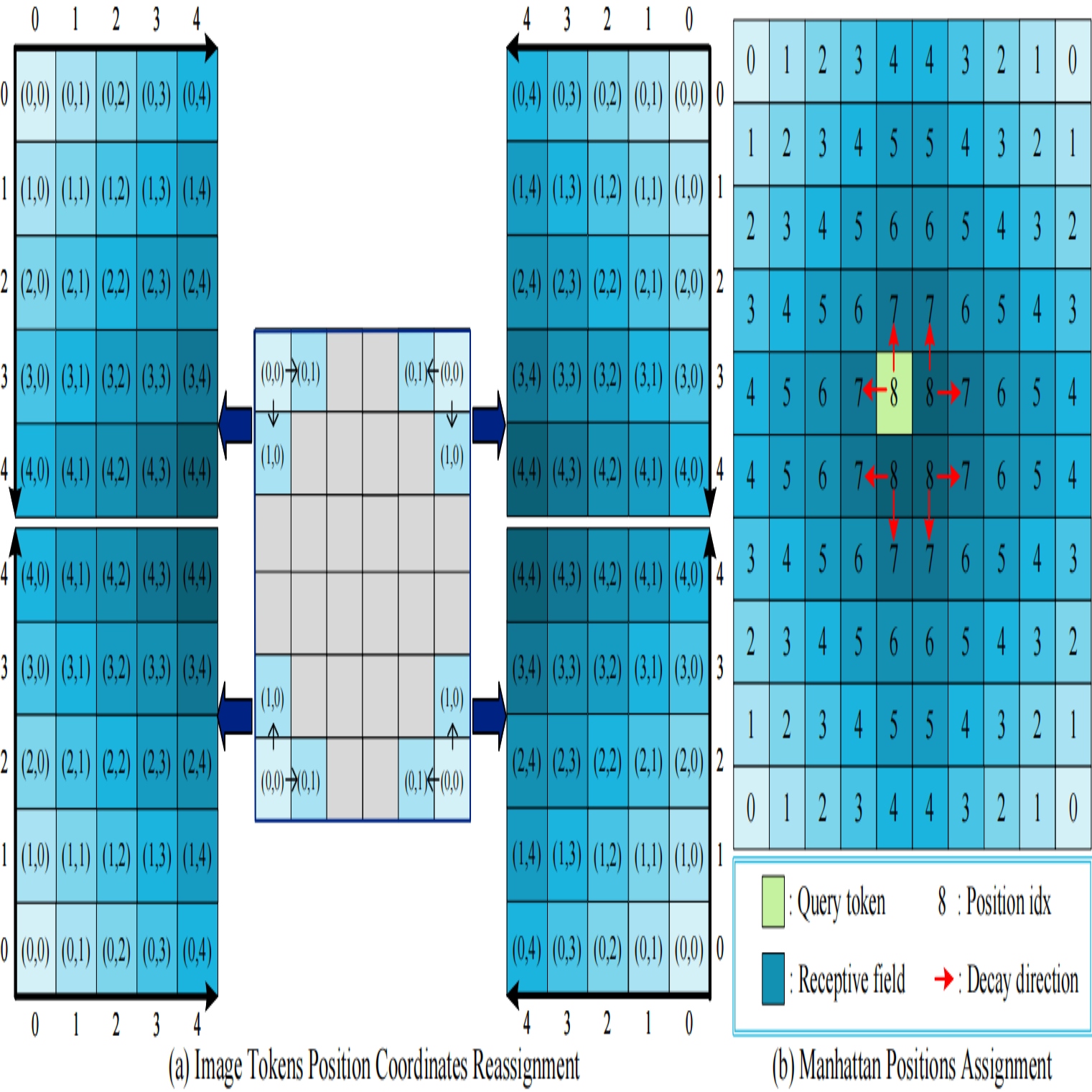
Hallucinations pose a significant challenge in Large Vision Language Models (LVLMs), with misalignment between multimodal features identified as a key contributing factor. This paper reveals the negative impact of the long-term decay in Rotary Position Encoding (RoPE), used for positional modeling in LVLMs, on multimodal alignment. Concretely, under long-term decay, instruction tokens exhibit uneven perception of image tokens located at different positions within the two-dimensional space: prioritizing image tokens from the bottom-right region since in the one-dimensional sequence, these tokens are positionally closer to the instruction tokens. This biased perception leads to insufficient image-instruction interaction and suboptimal multimodal alignment. We refer to this phenomenon as “image alignment bias.” To enhance instruction’s perception of image tokens at different spatial locations, we propose MCA-LLaVA, based on Manhattan distance, which extends the long-term decay to a two-dimensional, multi-directional spatial decay. MCA-LLaVA integrates the one-dimensional sequence order and two-dimensional spatial position of image tokens for positional modeling, mitigating hallucinations by alleviating image alignment bias. Experimental results of MCA-LLaVA across various hallucination and general benchmarks demonstrate its effectiveness and generality. The code can be accessed in https://github.com/ErikZ719/MCA-LLaVA.
@inproceedings{zhao2025mca-llava,title={MCA-LLaVA: Manhattan Causal Attention for Reducing Hallucination in Large Vision-Language Models},author={Zhao, Qiyan and Zhang, Xiaofeng and Li, Yiheng and Xing, Yun and Yuan, Xiaosong and Tang, Feilong and Fan, Sinan and Chen, Xuhang and Wang, Da-han and Zhang, Xu-yao},year={2025},booktitle={Proceedings of the ACM International Conference on Multimedia (MM)},publisher={ACM},address={Dublin, Ireland},pages={3981--3990},doi={10.1145/3746027.3755271},}
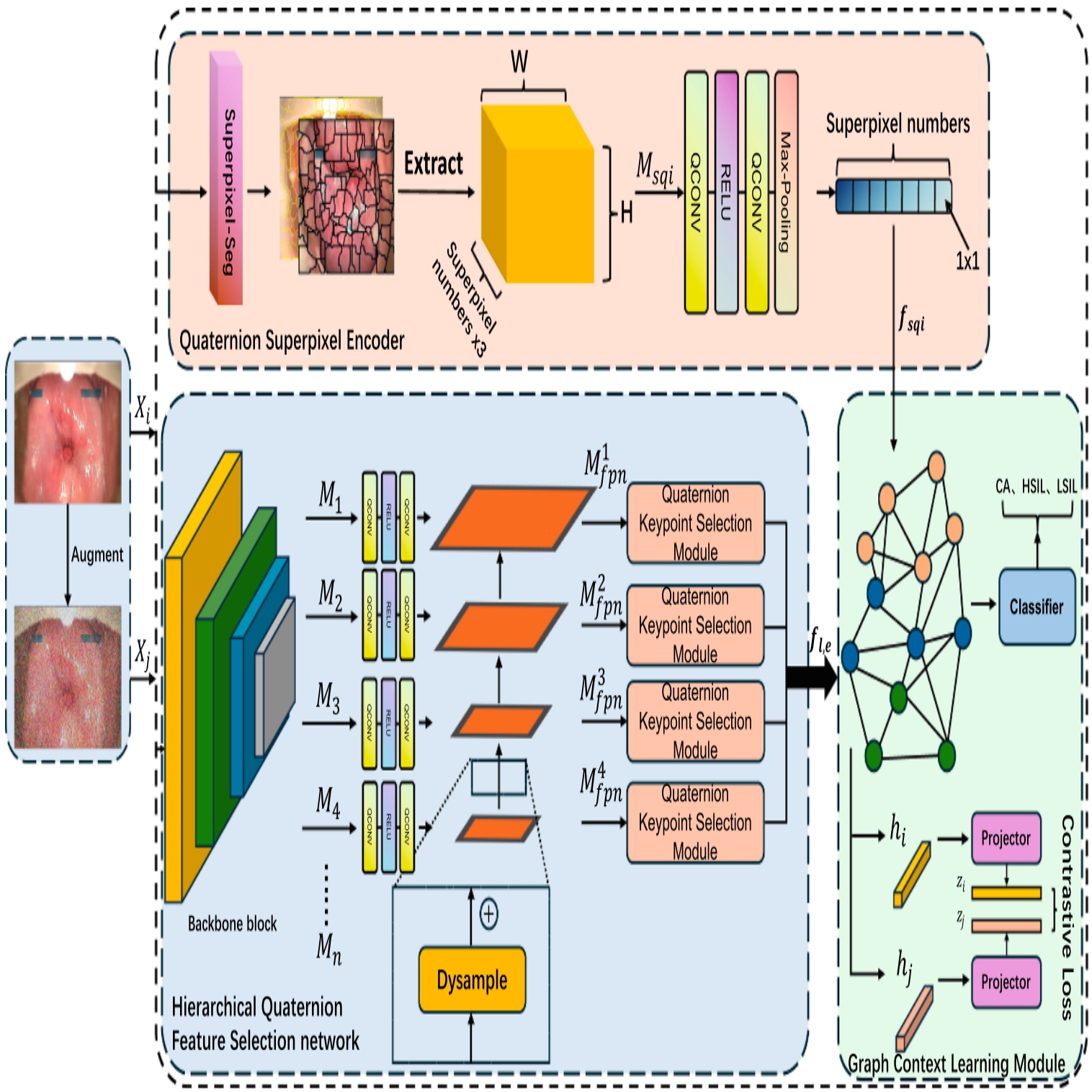
Superpixel-Enhanced Quaternion Feature Fusion and Contextualization Graph Contrastive Learning for Cervical Cancer Diagnosis
Coarse-grained classification methods have demonstrated robust performance across various image classification tasks. However, in colposcopy classification, these methods often struggle to effectively capture subtle lesion features. Fine-grained methods address this by merging multi-layer features to locate regions with high discriminative power. Nevertheless, such approaches frequently overlook contextual relationships between features and lose original shape information. Additionally, the similarity between lesion and normal regions further exacerbates classification challenges. To address these limitations, we propose SQG-net, a novel fine-grained classification method for cervical cancer diagnosis. SQG-net incorporates three innovative modules. First, the Quaternion Superpixel Encoder (QSE) preserves lesion shape and color features through superpixel segmentation and quaternion convolution. Next, the Hierarchical Quaternion Feature Selection (HQFS) network identifies fine-grained discriminative features, enhancing subtle feature differentiation. Finally, a Graph Context Learning Module (GCLM) captures contextual relationships between features. Additionally, contrastive learning is utilized to improve feature space separation, enhancing classification accuracy. The method was evaluated on both a private cervical imaging dataset and a publicly available dataset. SQG-net achieved significant improvements in classification accuracy, recording 88.97% on the private dataset and 79.11% on the publicly available dataset, establishing new state-of-the-art performance in cervical cancer classification. The code will be released upon conference acceptance.
@inproceedings{ma2025superpixel-enhanced,title={Superpixel-Enhanced Quaternion Feature Fusion and Contextualization Graph Contrastive Learning for Cervical Cancer Diagnosis},author={Ma, Jiajun and Huang, Guoheng and Yuan, Xiaochen and Chen, Xuhang and Chen, Jiawang and Cheng, Lianglun and Pun, Chi-Man and Zhong, Guo and Ye, Qingjian},year={2025},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Okinawa, Japan},pages={340--355},doi={10.1007/978-981-95-4378-6_24},}
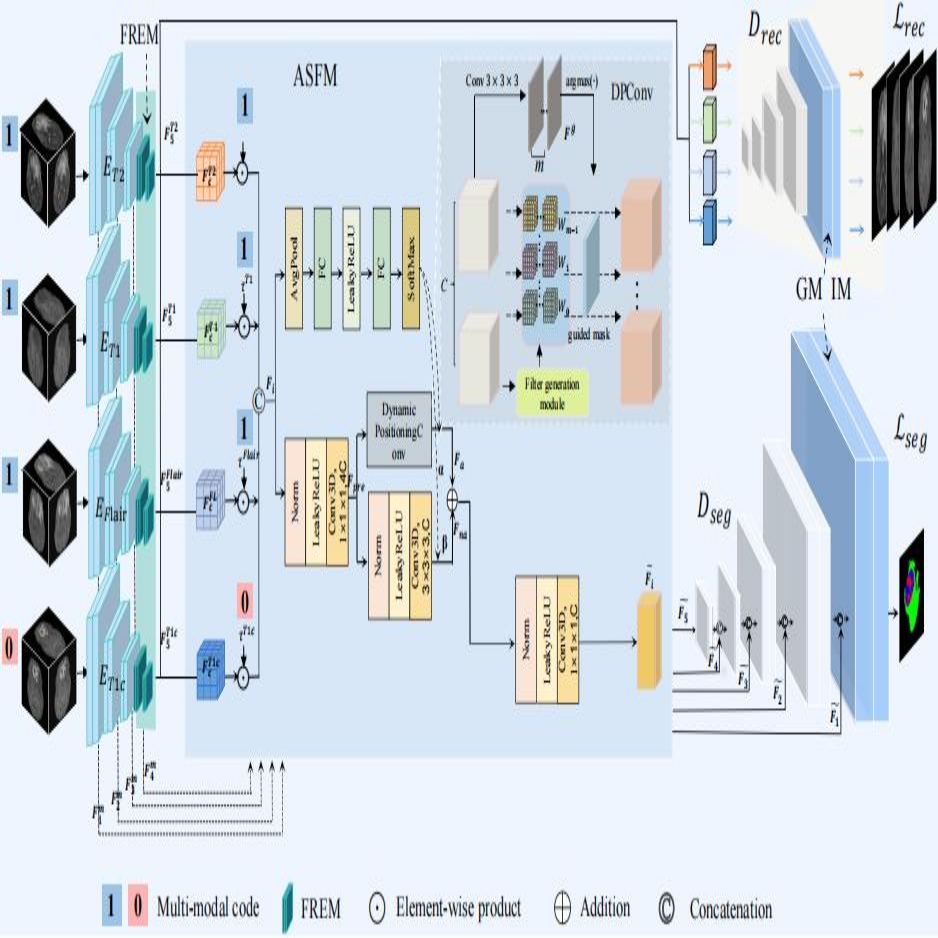
Multi-Scale Adaptively-Aware and Recalibration Network for Brain Tumor Segmentation with Missing Modalities
Accurate segmentation of brain tumor regions from multi-modal magnetic resonance imaging (MRI) is critical for clinical diagnosis. However, missing modalities is a common issue in clinical practice, where the unavailability of certain imaging modalities complicates the extraction and integration of complementary information across multiple modalities, leading to a decline in segmentation accuracy. Many existing models fail to adequately address subtle structural changes and boundary information within tumor regions when faced with missing modalities, limiting their ability to effectively adapt to complex tumor morphologies. To tackle these issues, The Multi-Scale Adaptively-Aware and Recalibration Network (MARNet) proposed in this paper can adaptively and fully explore the potential of multi-modal data under different combinations in the presence of missing modalities. MARNet incorporates a Feature Recalibration and Enhancement Module (FREM) that recalibrates and enhances the three-dimensional feature representation, emphasizing important fine-grained features of brain tumors. Subsequently, the Adaptive Shape-Aware Fusion Module (ASFM) fully exploits available modality information, achieving adaptive feature fusion for varying tumor locations and shapes, thereby compensating for information loss due to missing modalities. Furthermore, the Global and Multiscale Feature Integration Module (GMFIM) is designed to effectively capture long-range dependencies of tumors, particularly under conditions of missing modalities, aiding in the restoration and reconstruction of complete tumor structures. Extensive experiments on the BraTS2020, BraTS2018 and BraTS2015 datasets demonstrate that the proposed method surpasses several advanced brain tumor segmentation approaches in the context of missing modalities.
@inproceedings{li2025multi-scale,title={Multi-Scale Adaptively-Aware and Recalibration Network for Brain Tumor Segmentation with Missing Modalities},author={Li, Xin and Huang, Guoheng and Zheng, Zhipeng and Chen, Xuhang and Huang, Zhixin and Cheng, Lianglun},year={2025},booktitle={Proceedings of the International Joint Conference on Neural Networks (IJCNN)},address={Rome, Italy},pages={1--8},doi={10.1109/IJCNN64981.2025.11228228},publisher={IEEE}}
SGSP-MRI: Segmentation-Guided Survival Prediction from Multimodal MRI in Nasopharyngeal Carcinoma
Yue
Long, Guoheng
Huang†, Lianglun
Cheng, Xuanxuan
Ma
, Zhao
Li
, Xuhang
Chen, Siyue
Xie, Junkai
Zou
, and Zhongkun
Li
In International Conference on Signal Processing Systems (ICSPS), 2025
Nasopharyngeal carcinoma (NPC) is a prevalent head-and-neck malignancy in Southern China and Southeast Asia, where accurate prognostic prediction is essential for individualized treatment. Recently, multimodal magnetic resonance imaging (MRI) has shown superior performance over conventional clinical tumor-node-metastasis (TNM) staging for NPC survival prediction. However, most existing models process the entire MRI volume even though lesions occupy only a small fraction of voxels, thereby allowing background to swamp prognostic signals. Therefore, we propose Segmentation-Guided Survival Prediction from Multimodal MRI (SGSP-MRI), comprising two tightly coupled modules: Lesion Localization Segmentation Module (LLSM), based on an improved 3D U-Net, that precisely localizes the tumor and generates a high-confidence probability map to focus predictions on the lesion and peritumoral tissue; TargetGuided Cascaded Survival Module (TGCSM), which fuses this map with the original multimodal MRI in a guided early-fusion manner and applies cascaded multi-scale feature extraction to capture both fine-grained lesion morphology and global context. Extensive experiments on the Pearl River Delta Multicenter MRI Dataset for Nasopharyngeal Carcinoma (PRD-NPC-MRI), our self-collected multicenter dataset (n=1,769), demonstrate that SGSP-MRI achieves strong, reliable prognostic performance and consistently outperforms state-of-the-art methods.
@inproceedings{11347944,author={Long, Yue and Huang, Guoheng and Cheng, Lianglun and Ma, Xuanxuan and Li, Zhao and Chen, Xuhang and Xie, Siyue and Zou, Junkai and Li, Zhongkun},booktitle={International Conference on Signal Processing Systems (ICSPS)},title={SGSP-MRI: Segmentation-Guided Survival Prediction from Multimodal MRI in Nasopharyngeal Carcinoma},address={Chengdu, China},year={2025},pages={949-955},doi={10.1109/ICSPS66615.2025.11347944},publisher={IEEE},}
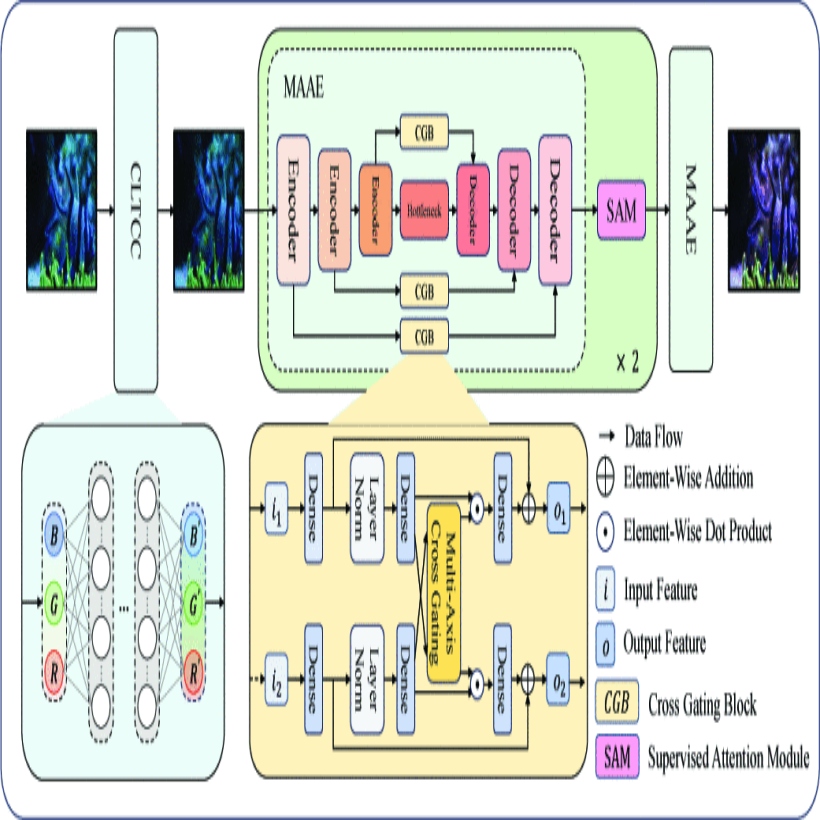
MAC-Lookup: Multi-Axis Conditional Lookup Model for Underwater Image Enhancement
Enhancing underwater images is crucial for exploration. These images face Enhancing underwater images is crucial for exploration. These images face visibility and color issues due to light changes, water turbidity, and bubbles. Traditional prior-based methods and pixel-based methods often fail, while deep learning lacks sufficient high-quality datasets. We introduce the Multi-Axis Conditional Lookup (MAC-Lookup) model, which enhances visual quality by improving color accuracy, sharpness, and contrast. It includes Conditional 3D Lookup Table Color Correction (CLTCC) for preliminary color and quality correction and Multi-Axis Adaptive Enhancement (MAAE) for detail refinement. This model prevents over-enhancement and saturation while handling underwater challenges. Extensive experiments show that MAC-Lookup excels in enhancing underwater images by restoring details and colors better than existing methods. The code is https://github.com/onlycatdoraemon/MAC-Lookup.
@inproceedings{11343365,author={Yi, Fanghai and Zheng, Zehong and Liang, Zexiao and Dong, Yihang and Fang, Xiyang and Wu, Wangyu and Chen, Xuhang},booktitle={IEEE International Conference on Systems, Man, and Cybernetics (SMC)},title={MAC-Lookup: Multi-Axis Conditional Lookup Model for Underwater Image Enhancement},year={2025},publisher={IEEE},address={Vienna, Austria},pages={1556-1561},doi={10.1109/SMC58881.2025.11343365},}
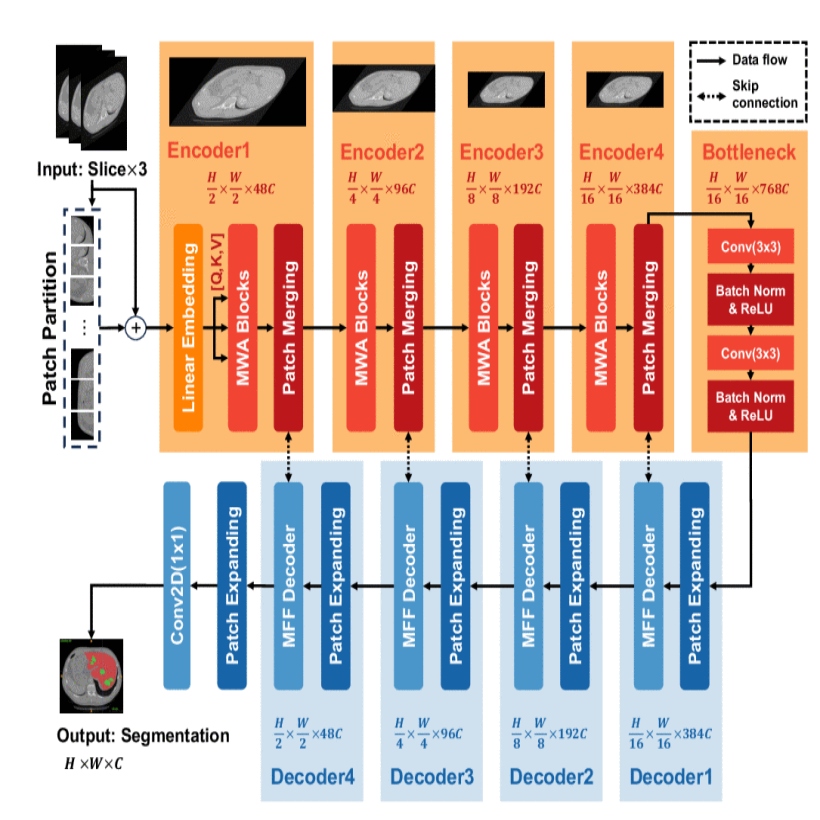
Medical image segmentation is a cornerstone of modern clinical diagnostics. While Vision Transformers that leverage shifted window-based self-attention have established new benchmarks in this field, they are often hampered by a critical limitation: their localized attention mechanism struggles to effectively fuse local details with global context. This deficiency is particularly detrimental to challenging tasks such as the segmentation of microtumors and miniature organs, where both finegrained boundary definition and broad contextual understanding are paramount. To address this gap, we propose HBFormer, a novel Hybrid-Bridge Transformer architecture. The ’Hybrid’ design of HBFormer synergizes a classic U-shaped encoder-decoder framework with a powerful Swin Transformer backbone for robust hierarchical feature extraction. The core innovation lies in its ’Bridge’ mechanism, a sophisticated nexus for multi-scale feature integration. This bridge is architecturally embodied by our novel Multi-Scale Feature Fusion (MFF) decoder. Departing from conventional symmetric designs, the MFF decoder is engineered to fuse multi-scale features from the encoder with global contextual information. It achieves this through a synergistic combination of channel and spatial attention modules, which are constructed from a series of dilated and depth-wise convolutions. These components work in concert to create a powerful feature bridge that explicitly captures long-range dependencies and refines object boundaries with exceptional precision. Comprehensive experiments on challenging medical image segmentation datasets, including multi-organ, liver tumor, and bladder tumor benchmarks, demonstrate that HBFormer achieves state-of-theart results, showcasing its outstanding capabilities in microtumor and miniature organ segmentation. Code and models are available at: https://github.com/lzeeorno/HBFormer.
@inproceedings{11357226,author={Zheng, Fuchen and Chen, Xinyi and Li, Weixuan and Li, Quanjun and Zhou, Junhua and Guo, Xiaojiao and Chen, Xuhang and Pun, Chi-Man and Zhou, Shoujun},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={HBFormer: A Hybrid-Bridge Transformer for Microtumor and Miniature Organ Segmentation},year={2025},pages={3343-3348},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11357226},publisher={IEEE}}
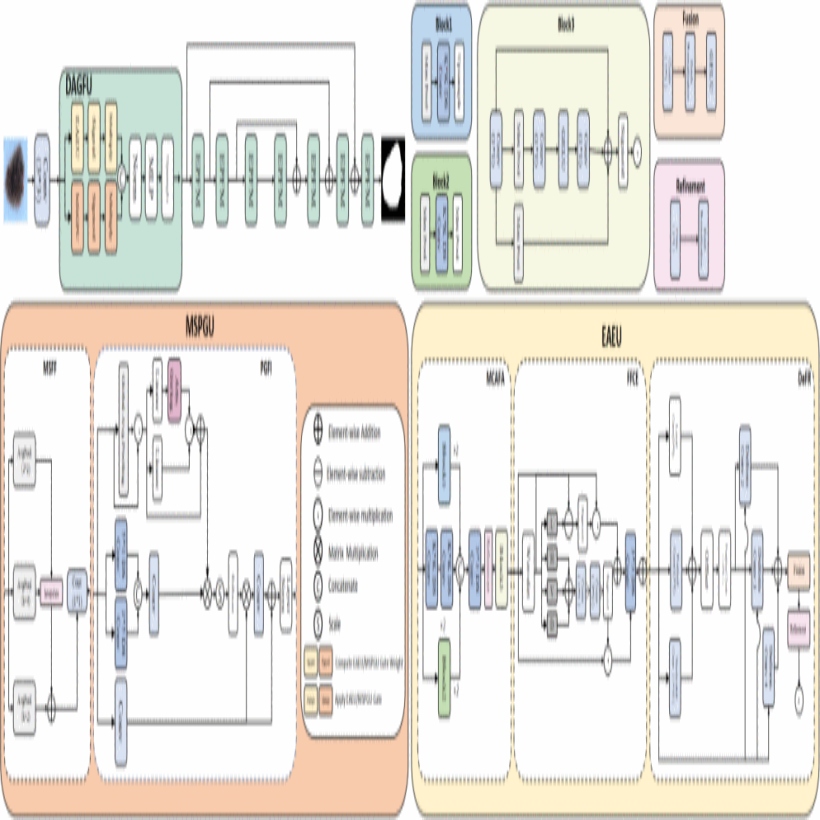
Medical image segmentation is vital for diagnosis, treatment planning, and disease monitoring but is challenged by complex factors like ambiguous edges and background noise. We introduce EEMS, a new model for segmentation, combining an Edge-Aware Enhancement Unit (EAEU) and a Multi-scale Prompt Generation Unit (MSPGU). EAEU enhances edge perception via multi-frequency feature extraction, accurately defining boundaries. MSPGU integrates high-level semantic and low-level spatial features using a prompt-guided approach, ensuring precise target localization. The Dual-Source Adaptive Gated Fusion Unit (DAGFU) merges edge features from EAEU with semantic features from MSPGU, enhancing segmentation accuracy and robustness. Tests on datasets like ISIC2018 confirm EEMS’s superior performance and reliability as a clinical tool.
@inproceedings{11356010,author={Xia, Han and Li, Quanjun and Li, Qian and Li, Zimeng and Ye, Hongbin and Liu, Yupeng and Li, Haolun and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={EEMS: Edge-Prompt Enhanced Medical Image Segmentation Based on Learnable Gating Mechanism},year={2025},pages={3006-3011},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11356010},publisher={IEEE}}
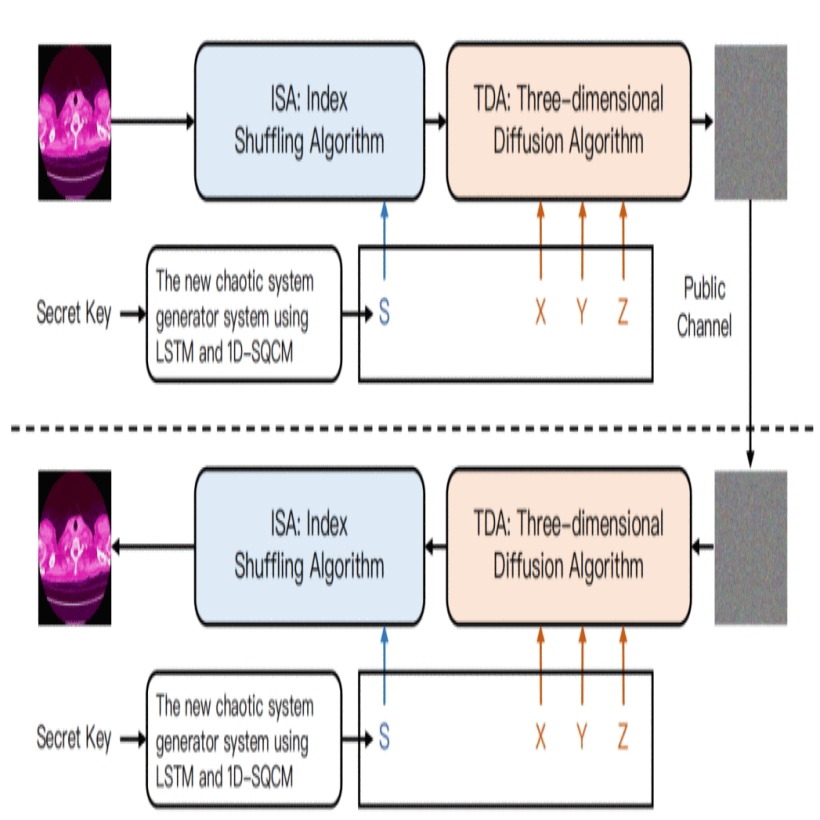
The rise of digital medical imaging, like MRI and CT, demands strong encryption to protect patient data in telemedicine and cloud storage. Chaotic systems are popular for image encryption due to their sensitivity and unique characteristics, but existing methods often lack sufficient security. This paper presents the Three-dimensional Diffusion Algorithm and Deep Learning Image Encryption system (TDADL-IE), built on three key elements. First, we propose an enhanced chaotic generator using an LSTM network with a 1D-Sine Quadratic Chaotic Map (1D-SQCM) for better pseudorandom sequence generation. Next, a new three-dimensional diffusion algorithm (TDA) is applied to encrypt permuted images. TDADL-IE is versatile for images of any size. Experiments confirm its effectiveness against various security threats. The code is available at https://github.com/QuincyQAQ/TDADL-IE.
@inproceedings{11357074,author={Zhou, Junhua and Li, Quanjun and Li, Weixuan and Yu, Guang and Shao, YiHua and Dong, Yihang and Wang, Mengqian and Li, Zimeng and Gong, Changwei and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={TDADL-IE: A Deep Learning-Driven Cryptographic Architecture for Medical Image Security},year={2025},pages={3377-3382},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11357074},publisher={IEEE},}
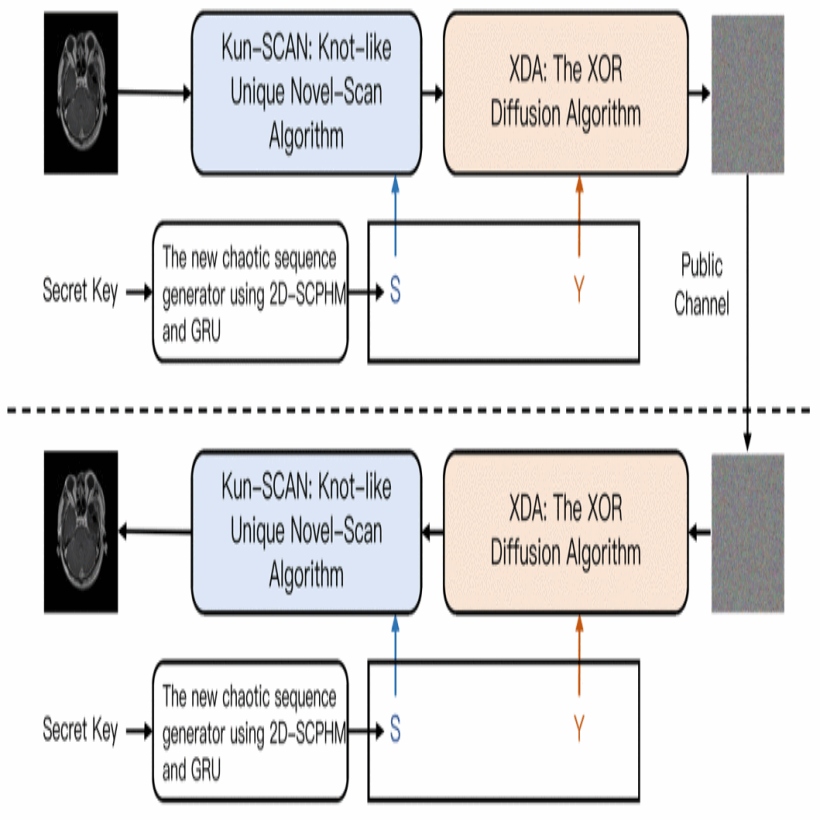
Chaotic systems play a key role in modern image encryption due to their sensitivity to initial conditions, ergodicity, and complex dynamics. However, many existing chaos-based encryption methods suffer from vulnerabilities, such as inade-quate permutation and diffusion, and suboptimal pseudorandom properties. To address these issues, this paper presents the Knot-like Unique Novel-Scan Image Encryption (Kun-IE). The framework comprises two main components: The 2D Sin–Cos Pi Hyperchaotic Map (2D-SCPHM), which provides a broader chaotic range and superior pseudorandom sequence generation, and the Knot-like Unique Novel-Scan Algorithm (Kun-SCAN), a novel permutation mechanism that markedly reduces pixel correlations and enhances resistance to statistical attacks. Kun-IE is flexible and supports encryption for images of any size. Experimental results and security analyses demonstrate its robustness against various cryptanalytic attacks, making it a strong solution for secure image communication. The code is available at this link.
@inproceedings{11356029,author={Li, Weixuan and Yu, Guang and Li, Quanjun and Zhou, Junhua and Chen, Jiajun and Dong, Yihang and Wang, Mengqian and Li, Zimeng and Gong, Changwei and Tang, Lin and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={Elevating Medical Image Security: A Cryptographic Framework Integrating Hyperchaotic Map and GRU},year={2025},pages={2371-2376},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11356029},publisher={IEEE},}
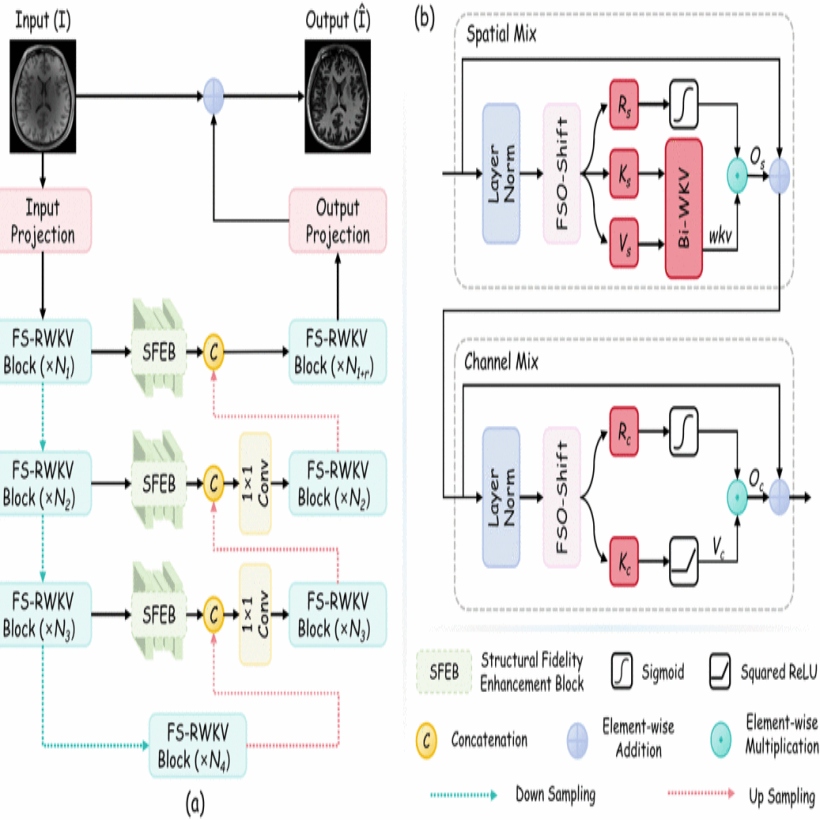
Ultra-high-field 7T MRI offers enhanced spatial resolution and tissue contrast that enable the detection of subtle pathological changes in neurological disorders. However, the limited availability of 7T scanners restricts widespread clinical adoption due to substantial infrastructure costs and technical demands. Computational approaches for synthesizing 7T-quality images from accessible 3T acquisitions present a viable solution to this accessibility challenge. Existing CNN approaches suffer from limited spatial coverage, while Transformer models demand excessive computational overhead. RWKV architectures offer an efficient alternative for global feature modeling in medical image synthesis, combining linear computational complexity with strong long-range dependency capture. Building on this foundation, we propose Frequency Spatial-RWKV (FS-RWKV), an RWKV-based framework for 3T-to-7T MRI translation. To better address the challenges of anatomical detail preservation and global tissue contrast recovery, FS- RWKV incorporates two key modules: (1) Frequency-Spatial Omnidirectional Shift (FSO-Shift), which performs discrete wavelet decomposition followed by omnidirectional spatial shifting on the low-frequency branch to enhance global contextual representation while preserving high-frequency anatomical details; and (2) Structural Fidelity Enhancement Block (SFEB), a module that adaptively reinforces anatomical structure through frequency-aware feature fusion. Comprehensive experiments on UNC and BNU datasets demonstrate that FS- RWKV consistently outperforms existing CNN-, Transformer-, GAN-, and RWKV-based baselines across both T1 wand T2w modalities, achieving superior anatomical fidelity and perceptual quality.
@inproceedings{11356228,author={Lei, Yingtie and Li, Zimeng and Pun, Chi-Man and Liu, Yupeng and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={FS-RWKV: Leveraging Frequency Spatial-Aware RWKV for 3T-to-7T MRI Translation},year={2025},pages={1-6},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11356228},publisher={IEEE},}
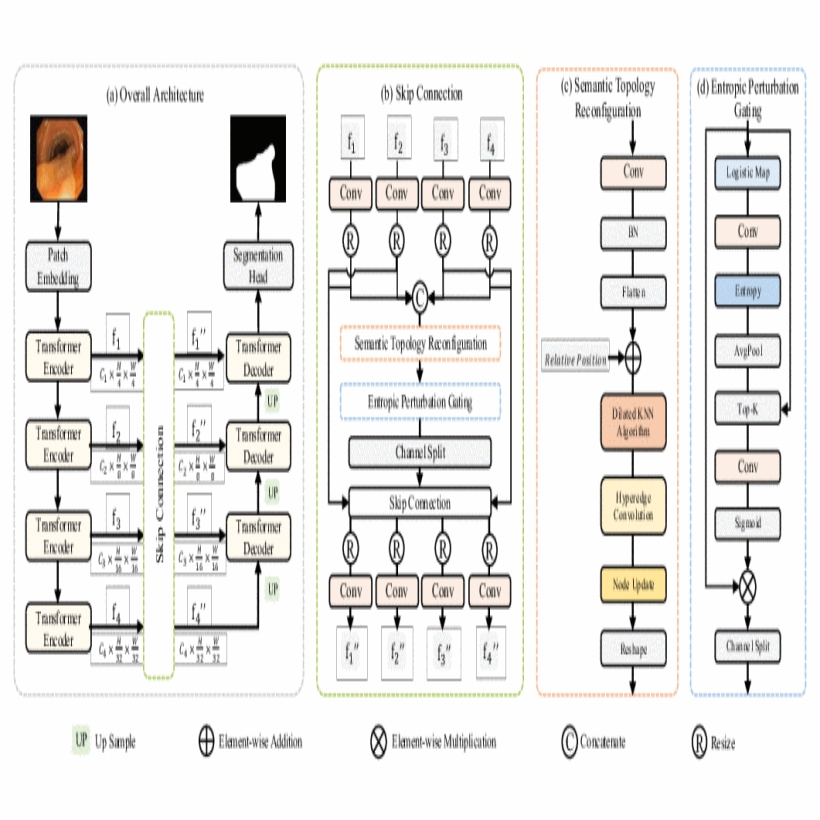
In medical image segmentation, skip connections are used to merge global context and reduce the semantic gap between encoder and decoder. Current methods often struggle with limited structural representation and insufficient contextual modeling, affecting generalization in complex clinical scenarios. We propose the DTEA model, featuring a new skip connection framework with the Semantic Topology Reconfiguration (STR) and Entropic Perturbation Gating (EPG) modules. STR reorganizes multi-scale semantic features into a dynamic hypergraph to better model cross-resolution anatomical dependencies, enhancing structural and semantic representation. EPG assesses channel stability after perturbation and filters high-entropy channels to emphasize clinically important regions and improve spatial attention. Extensive experiments on three benchmark datasets show our framework achieves superior segmentation accuracy and better generalization across various clinical settings. The code is available at https://github.com/LWX-Research/DTEA.
@inproceedings{11356772,author={Li, Weixuan and Li, Quanjun and Yu, Guang and Yang, Song and Li, Zimeng and Pun, Chi-Man and Liu, Yupeng and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={DTEA: Dynamic Topology Weaving and Instability-Driven Entropic Attenuation for Medical Image Segmentation},year={2025},pages={2383-2388},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11356772},publisher={IEEE},}
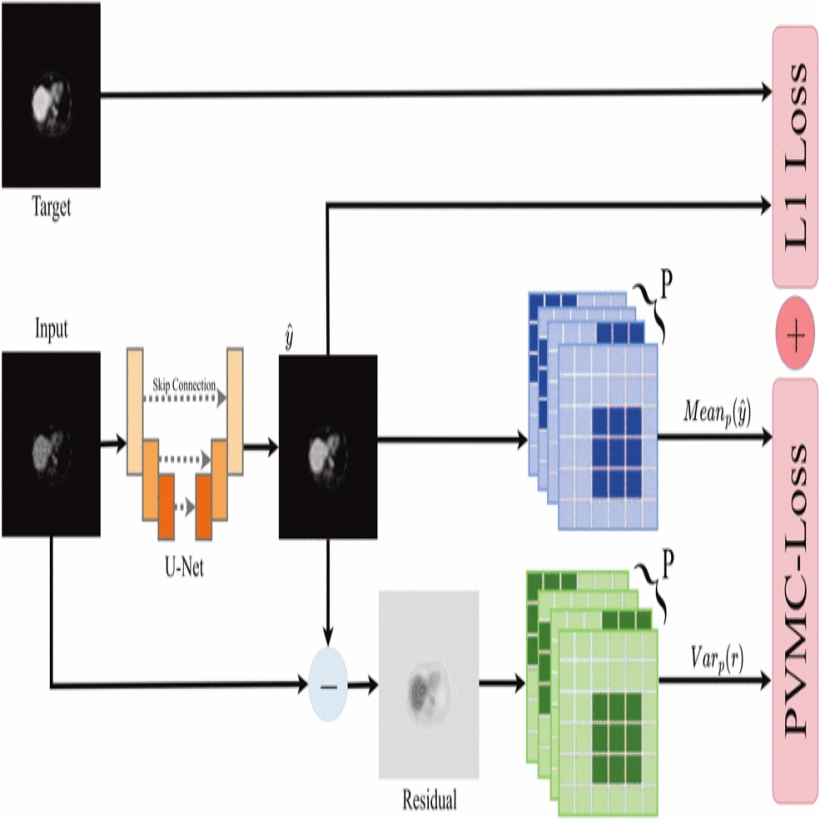
Positron Emission Tomography (PET) is crucial in medicine, but its clinical use is limited due to high signal-to-noise ratio doses increasing radiation exposure. Lowering doses increases Poisson noise, which current denoising methods fail to handle, causing distortions and artifacts. We propose a Poisson Consistent U-Net (PC-UNet) model with a new Poisson Variance and Mean Consistency Loss (PVMC-Loss) that incorporates physical data to improve image fidelity. PVMC- Loss is statistically unbiased in variance and gradient adaptation, acting as a Generalized Method of Moments implementation, offering robustness to minor data mismatches. Tests on PET datasets show PC-UNet improves physical consistency and image fidelity, proving its ability to integrate physical information effectively.
@inproceedings{11356275,author={Shi, Yang and Wang, Jingchao and Lu, Liangsi and Huang, Mingxuan and He, Ruixin and Xie, Yifeng and Liu, Hanqian and Guo, Minzhe and Liang, Yangyang and Zhang, Weipeng and Li, Zimeng and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={PC-UNet: An Enforcing Poisson Statistics U-Net for Positron Emission Tomography Denoising},year={2025},pages={2748-2753},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11356275},publisher={IEEE}}
Medical image segmentation remains fundamentally challenged by the complexity of anatomical structures and severe class imbalance. Existing methods often fall short in multi-scale feature integration and long-tailed distribution modeling, limiting their ability to simultaneously capture fine-grained local structures and holistic contextual semantics. To overcome these issues, we propose HAFT, a hierarchical attentional fusion transformer for adaptive feature fusion in medical image segmentation. We further introduce a Bayesian Adaptive Loss (BAL), which incorporates Bayesian uncertainty modeling to effectively alleviate the long-tailed distribution prevalent in medical datasets. Extensive experiments on multiple public benchmarks demonstrate that our method consistently outperforms existing approaches, particularly in segmenting intricate anatomical regions and rare pathological lesions. The code is available at https://github.com/QuincyQAQ/HAFT.
@inproceedings{11356858,author={Li, Quanjun and Li, Weixuan and Zheng, Fuchen and Zhou, Junhua and Xia, Han and Gong, Changwei and Li, Zimeng and Shao, Yihua and Chen, Xuhang},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},title={HAFT: Hierarchical Attentional Fusion Transformer for Adaptive Feature Fusion in Medical Image Segmentation},year={2025},pages={2377-2382},address={Wuhan, China},doi={10.1109/BIBM66473.2025.11356858},publisher={IEEE},}
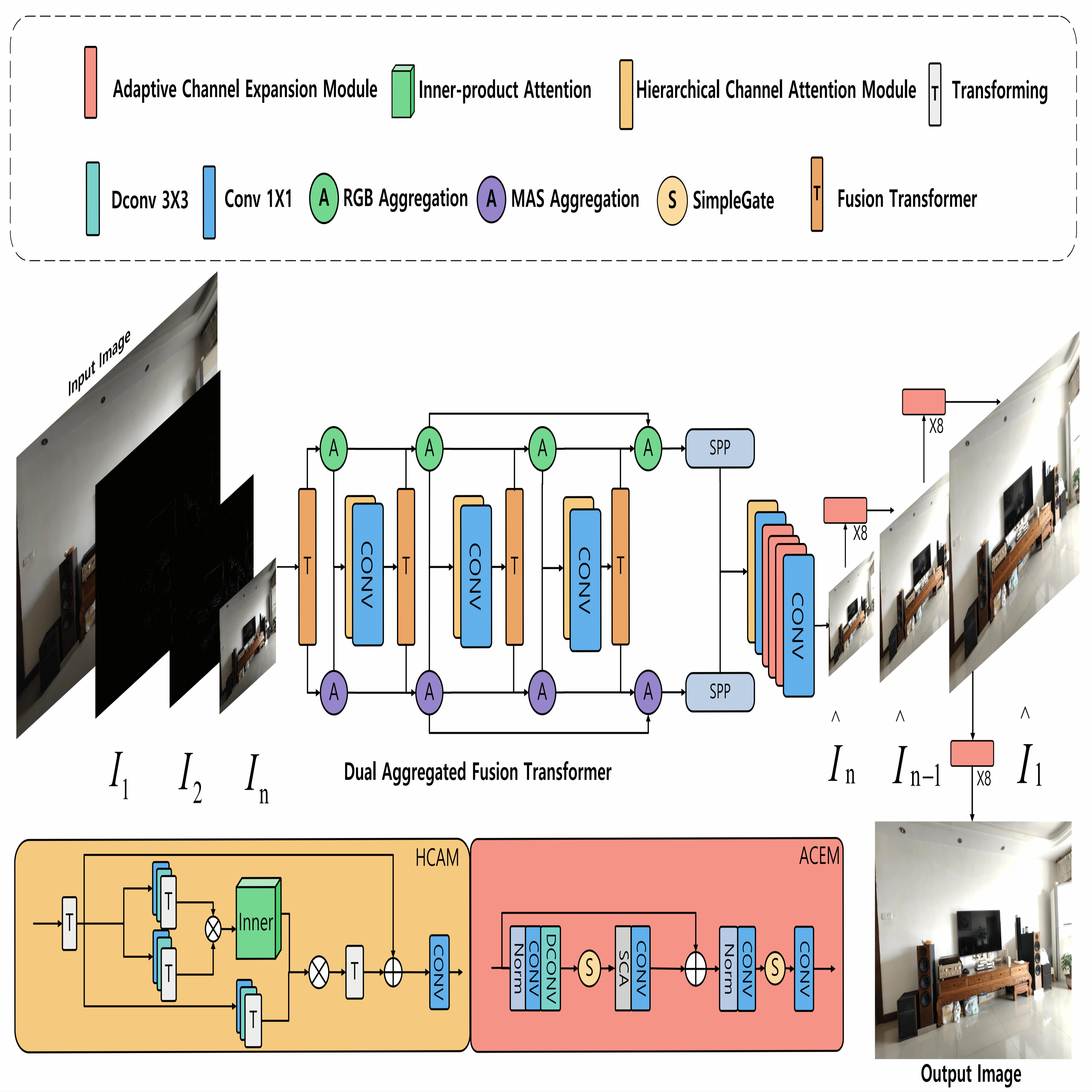
Vignetting commonly occurs as a degradation in images resulting from factors such as lens design, improper lens hood usage, and limitations in camera sensors. This degradation affects image details, color accuracy, and presents challenges in computational photography. Existing vignetting removal algorithms predominantly rely on ideal physics assumptions and hand-crafted parameters, resulting in the ineffective removal of irregular vignetting and suboptimal results. Moreover, the substantial lack of real-world vignetting datasets hinders the objective and comprehensive evaluation of vignetting removal. To address these challenges, we present VigSet, a pioneering dataset for vignetting removal. VigSet includes 983 pairs of both vignetting and vignetting-free high-resolution (over 4k) real-world images under various conditions. In addition, We introduce DeVigNet, a novel frequency-aware Transformer architecture designed for vignetting removal. Through the Laplacian Pyramid decomposition, we propose the Dual Aggregated Fusion Transformer to handle global features and remove vignetting in the low-frequency domain. Additionally, we propose the Adaptive Channel Expansion Module to enhance details in the high-frequency domain. The experiments demonstrate that the proposed model outperforms existing state-of-the-art methods. The code, models, and dataset are available at https://github.com/CXH-Research/DeVigNet.
@inproceedings{luo2024devignet,title={Devignet: High-Resolution Vignetting Removal via a Dual Aggregated Fusion Transformer with Adaptive Channel Expansion},author={Luo, Shenghong and Chen, Xuhang and Chen, Weiwen and Li, Zinuo and Wang, Shuqiang and Pun, Chi-Man},year={2024},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},publisher={Association for the Advancement of Artificial Intelligence},address={Vancouver, Canada},pages={4000--4008},doi={10.1609/AAAI.V38I5.28193},}
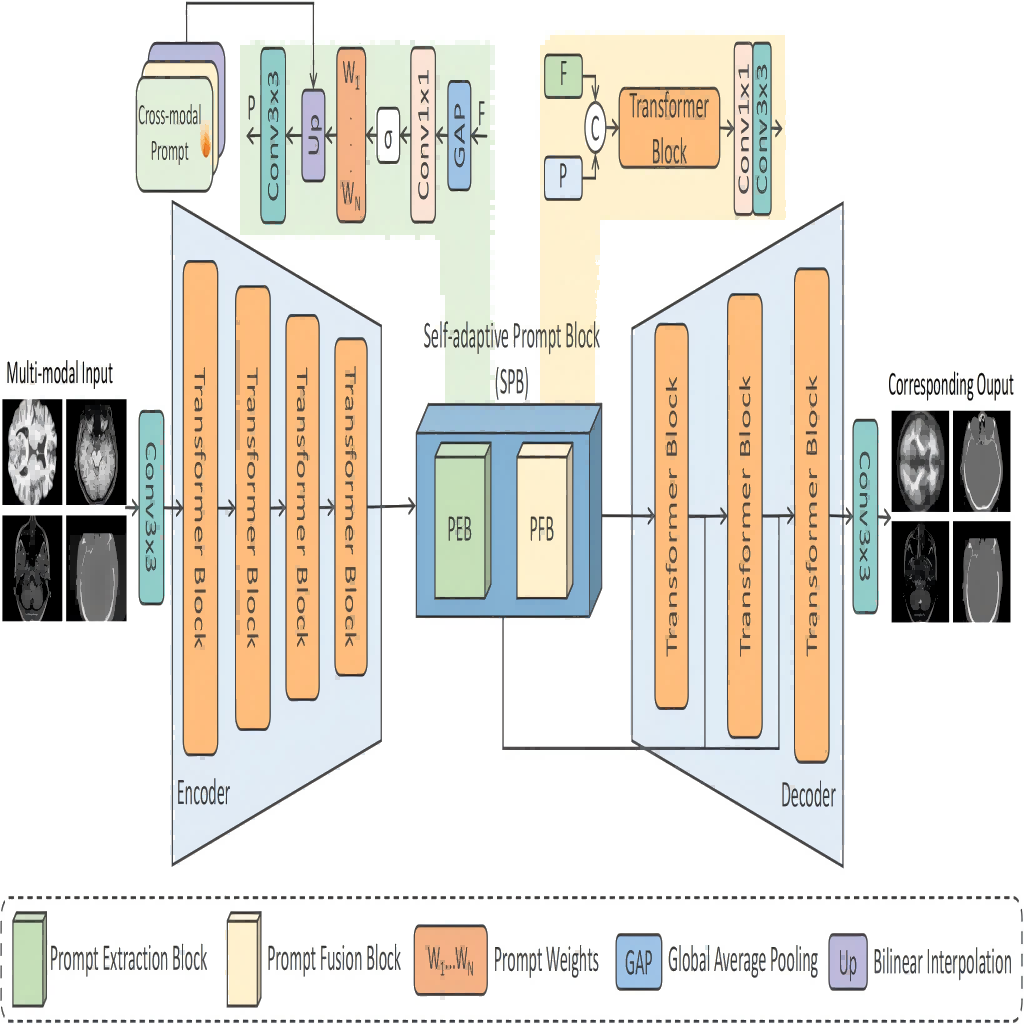
The ability to translate medical images across different modalities is crucial for synthesizing missing data and aiding in clinical diagnosis. However, existing learning-based techniques have limitations when it comes to capturing cross-modal and global features. These techniques are often tailored to specific pairs of modalities, limiting their practical utility, especially considering the variability of missing modalities in different cases. In this study, we introduce MedPrompt, a multi-task framework designed to efficiently translate diverse modalities. Our framework incorporates the Self-adaptive Prompt Block, which dynamically guides the translation network to handle different modalities effectively. To encode the cross-modal prompt efficiently, we introduce the Prompt Extraction Block and the Prompt Fusion Block. Additionally, we leverage the Transformer model to enhance the extraction of global features across various modalities. Through extensive experimentation involving five datasets and four pairs of modalities, we demonstrate that our proposed model achieves state-of-the-art visual quality and exhibits excellent generalization capability. The results highlight the effectiveness and versatility of MedPrompt in addressing the challenges associated with cross-modal medical image translation.
@inproceedings{chen2024medprompt,title={Medprompt: Cross-modal prompting for multi-task medical image translation},author={Chen, Xuhang and Luo, Shenghong and Pun, Chi-Man and Wang, Shuqiang},year={2024},booktitle={Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV)},publisher={Springer},address={Urumqi, China},pages={61--75},doi={10.1007/978-981-97-8496-7_5},}
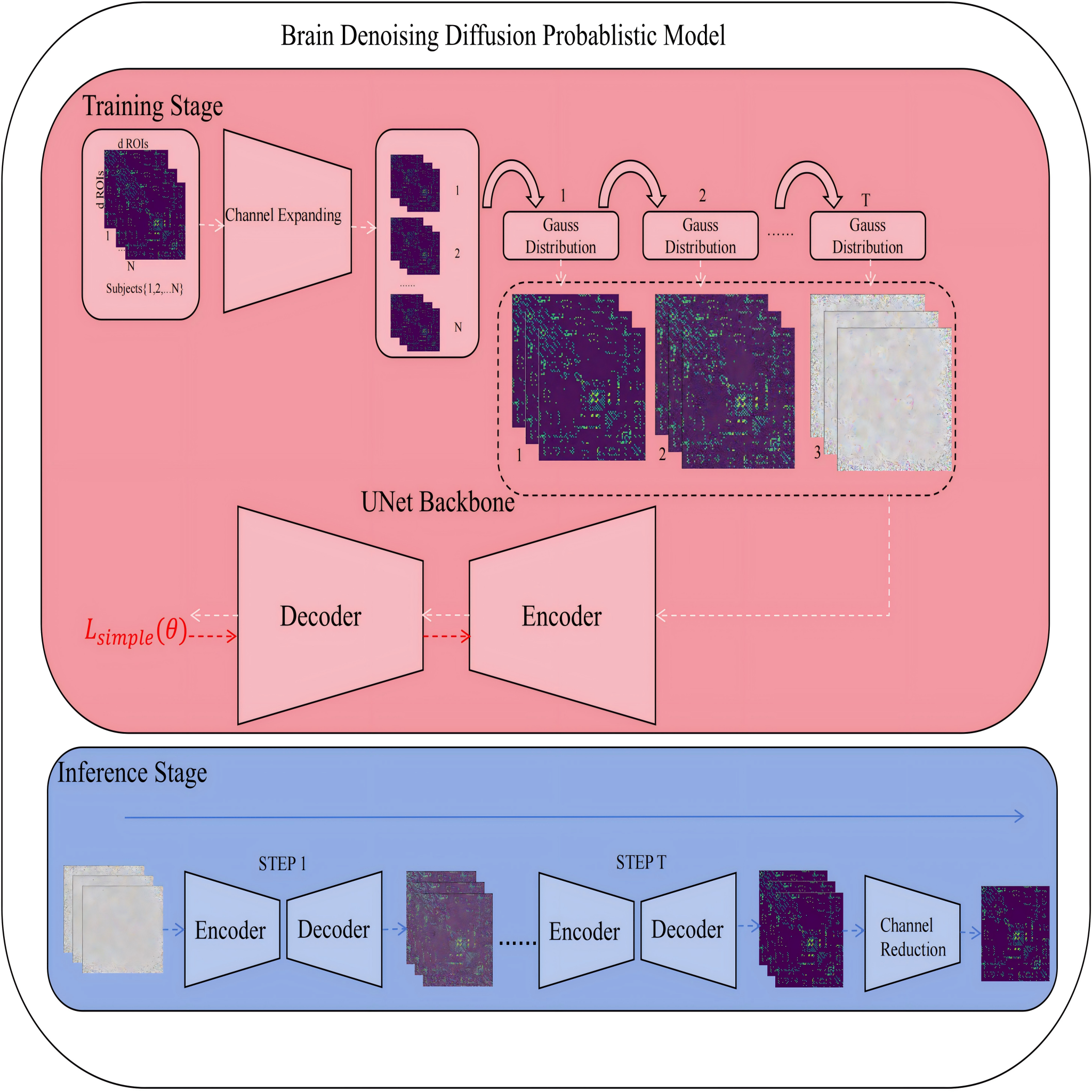
Structural Brain Network Generation via Brain Denoising Diffusion Probabilistic Model
Hongjie
Jiang
, Xuhang
Chen, Changhong
Jing, and Shuqiang
Wang†
In International Conference on AI in Healthcare (AIiH), 2024
Alzheimer’s disease (AD) significantly impairs the quality of life for a vast patient population and poses treatment challenges, partly due to its elusive pathophysiological mechanisms. The analysis of structural brain networks is fundamental to elucidating these mechanisms. However, acquiring data on such networks is non-trivial, hindered by the slow generation of structural brain network data and the complexities involved in obtaining DTI, a key requisite for their construction. In this study, we introduce a brain denoising diffusion probabilistic model designed to synthesize structural brain networks at various stages of AD, thereby mitigating the difficulties inherent in data acquisition. We trained this model on the ADNI dataset, utilizing two sets of data: one comprising structural brain networks produced by PANDA, and the other amalgamating these PANDA-generated networks with those synthesized by our model. Both datasets were employed to train a DiffPool for subsequent diagnostic tasks. It can be seen that the brain networks generated by the brain denoising diffusion probabilistic model are beneficial for structural brain networks in downstream diagnostic tasks.
@inproceedings{jiang2024structural,title={Structural Brain Network Generation via Brain Denoising Diffusion Probabilistic Model},author={Jiang, Hongjie and Chen, Xuhang and Jing, Changhong and Wang, Shuqiang},year={2024},booktitle={International Conference on AI in Healthcare (AIiH)},publisher={Springer},address={Swansea, United Kingdom},pages={264--277},doi={10.1007/978-3-031-67278-1_21},}
Specular highlights are a common issue in images captured under direct light sources. They are caused by the reflection of light sources on the surface of objects, which can lead to overexposure and loss of detail. Existing methods for specular highlight removal often rely on hand-crafted features and heuristics, which limits their effectiveness. In this paper, we propose a dual-hybrid attention network for specular highlight removal. The network consists of two branches: a spatial attention branch and a channel attention branch. The spatial attention branch focuses on the spatial distribution of specular highlights, while the channel attention branch emphasizes the importance of different channels. The two branches are combined to form a dual-hybrid attention network, which effectively removes specular highlights while preserving image details. Experimental results show that the proposed network outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics.
@inproceedings{guo2024dual-hybrid,title={Dual-Hybrid Attention Network for Specular Highlight Removal},author={Guo, Xiaojiao and Chen, Xuhang and Luo, Shenghong and Wang, Shuqiang and Pun, Chi-Man},year={2024},booktitle={Proceedings of the ACM International Conference on Multimedia (MM)},publisher={ACM},address={Melbourne, VIC, Australia},pages={10173--10181},doi={10.1145/3664647.3680745},}
In medical image segmentation, specialized computer vision techniques, notably transformers grounded in attention mechanisms and residual networks employing skip connections, have been instrumental in advancing performance. Nonetheless, previous models often falter when segmenting small, irregularly shaped tumors. To this end, we introduce SMAFormer, an efficient, Transformer-based architecture that fuses multiple attention mechanisms for enhanced segmentation of small tumors and organs. SMAFormer can capture both local and global features for medical image segmentation. The architecture comprises two pivotal components. First, a Synergistic Multi-Attention (SMA) Transformer block is proposed, which has the benefits of Pixel Attention, Channel Attention, and Spatial Attention for feature enrichment. Second, addressing the challenge of information loss incurred during attention mechanism transitions and feature fusion, we design a Feature Fusion Modulator. This module bolsters the integration between the channel and spatial attention by mitigating reshaping-induced information attrition. To evaluate our method, we conduct extensive experiments on various medical image segmentation tasks, including liver with tumor and bladder with tumor segmentation, achieving state-of-the-art results. Code and models are available at: \urlhttps://github.com/lzeeorno/SMAFormer.
@inproceedings{zheng2024smaformer,title={SMAFormer: Synergistic Multi-Attention Transformer for Medical Image Segmentation},author={Zheng, Fuchen and Chen, Xuhang and Liu, Weihuang and Li, Haolun and Lei, Yingtie and He, Jiahui and Pun, Chi-Man and Zhou, Shounjun},year={2024},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},publisher={IEEE},address={Lisbon, Portugal},pages={4048--4053},doi={10.1109/BIBM62325.2024.10822736},}
Accurate prediction of mortality in nasopharyngeal carcinoma (NPC), a complex malignancy particularly challenging in advanced stages, is crucial for optimizing treatment strategies and improving patient outcomes. However, this predictive process is often compromised by the high-dimensional and heterogeneous nature of NPC-related data, coupled with the pervasive issue of incomplete multi-modal data, manifesting as missing radiological images or incomplete diagnostic reports. Traditional machine learning approaches suffer significant performance degradation when faced with such incomplete data, as they fail to effectively handle the high-dimensionality and intricate correlations across modalities. Even advanced multi-modal learning techniques like Transformers struggle to maintain robust performance in the presence of missing modalities, as they lack specialized mechanisms to adaptively integrate and align the diverse data types, while also capturing nuanced patterns and contextual relationships within the complex NPC data. To address these problem, we introduce IMAN: an adaptive network for robust NPC mortality prediction with missing modalities. IMAN features three integrated modules: the Dynamic Cross-Modal Calibration (DCMC) module employs adaptive, learnable parameters to scale and align medical images and field data; the Spatial-Contextual Attention Integration (SCAI) module enhances traditional Transformers by incorporating positional information within the self-attention mechanism, improving multi-modal feature integration; and the Context-Aware Feature Acquisition (CAFA) module adjusts convolution kernel positions through learnable offsets, allowing for adaptive feature capture across various scales and orientations in medical image modalities. Extensive experiments on our proprietary NPC dataset demonstrate IMAN’s robustness and high predictive accuracy, even with missing data. Compared to existing methods, IMAN consistently outperforms in scenarios with incomplete data, representing a significant advancement in mortality prediction for medical diagnostics and treatment planning. Our code is available at \urlhttps://github.com/king-huoye/BIBM-2024/tree/master.
@inproceedings{huo2024iman,title={IMAN: An Adaptive Network for Robust NPC Mortality Prediction with Missing Modalities},author={Huo, Yejing and Huang, Guoheng and Cheng, Lianglun and He, Jianbin and Chen, Xuhang and Yuan, Xiaochen and Zhong, Guo and Pun, Chi-Man},year={2024},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},publisher={IEEE},address={Lisbon, Portugal},pages={2074--2079},doi={10.1109/BIBM62325.2024.10822792},}
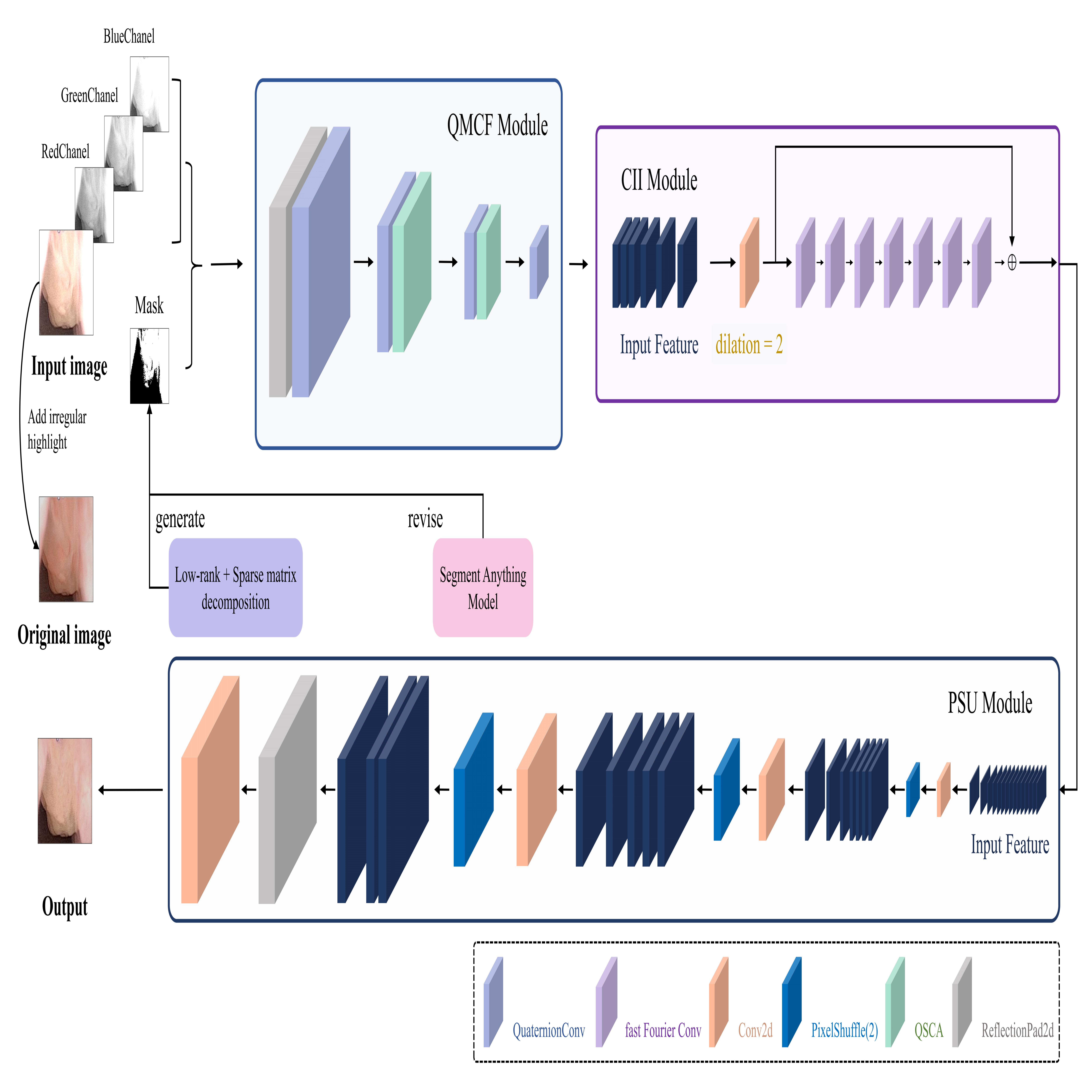
Due to the built-in light source within the endoscope, the illumination of bodily mucous can cause the formation of highlight regions due to reflection. This not only interferes with the diagnosis conducted by doctors but also poses a challenge to subsequent computer vision tasks. To tackle this issue, we introduce FAQNet, a network specifically designed for endoscopic image highlight removal. FAQNet seamlessly integrates multi-channel information leveraging quaternion convolution and spatial channel attention within our Quaternion Multi-Channel Fusion (QMCF) Module. This allows it to capture intricate details of color, texture, spatial information, and highlight characteristics within the imaged organ. Additionally, by employing frequency domain transformation and dilated convolution, the Contextual Information Integration (CII) Module effectively enlarges the receptive field, organizing contextual information between highlight regions and their surrounding areas. Lastly, the PixelShuffle Upsampling (PSU) Module generates the restored image. We validate our model’s performance on two benchmark datasets, demonstrating its superiority over existing highlight removal methodologies.
@inproceedings{zhu2024faqnet,title={FAQNet: Frequency-Aware Quaternion Network for Endoscopic Highlight Removal},author={Zhu, Dingzhou and Huang, Guoheng and Yuan, Xiaochen and Chen, Xuhang and Zhong, Guo and Pun, Chi-Man and Deng, Jie},year={2024},booktitle={Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM)},publisher={IEEE},address={Lisbon, Portugal},pages={1408--1413},doi={10.1109/BIBM62325.2024.10822449},}
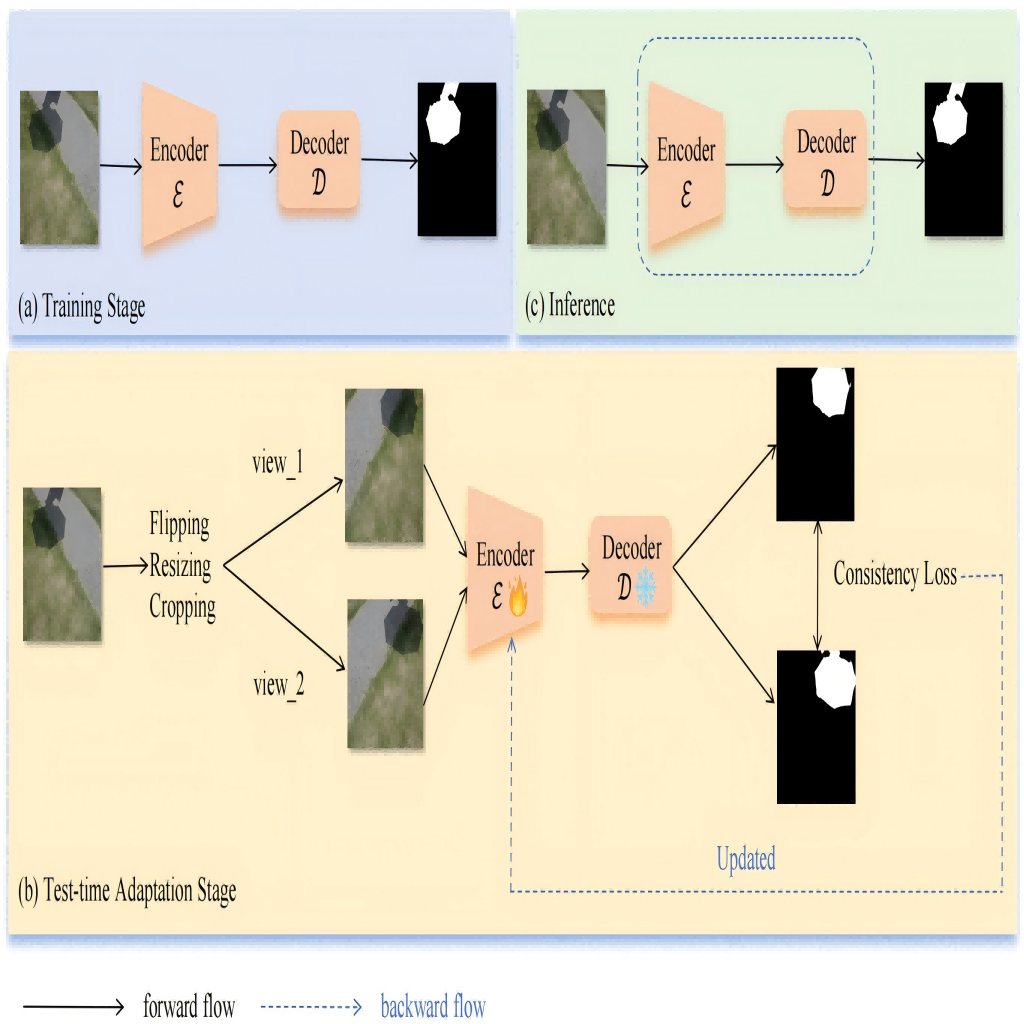
Test-Time Intensity Consistency Adaptation for Shadow Detection
Leyi
Zhu, Weihuang
Liu
, Xinyi
Chen
, Zimeng
Li
, Xuhang
Chen
, Zhen
Wang, and Chi-Man
Pun†
In International Conference on Neural Information Processing (ICONIP), 2024
Shadow detection is crucial for accurate scene understanding in computer vision, yet it is challenged by the diverse appearances of shadows caused by variations in illumination, object geometry, and scene context. Deep learning models often struggle to generalize to real-world images due to the limited size and diversity of training datasets. To address this, we introduce TICA, a novel framework that leverages light-intensity information during test-time adaptation to enhance shadow detection accuracy. TICA exploits the inherent inconsistencies in light intensity across shadow regions to guide the model toward a more consistent prediction. A basic encoder-decoder model is initially trained on a labeled dataset for shadow detection. Then, during the testing phase, the network is adjusted for each test sample by enforcing consistent intensity predictions between two augmented input image versions. This consistency training specifically targets both foreground and background intersection regions to identify shadow regions within images accurately for robust adaptation. Extensive evaluations on the ISTD and SBU shadow detection datasets reveal that TICA significantly demonstrates that TICA outperforms existing state-of-the-art methods, achieving superior results in balanced error rate (BER).
@inproceedings{zhu2024test-time,title={Test-Time Intensity Consistency Adaptation for Shadow Detection},author={Zhu, Leyi and Liu, Weihuang and Chen, Xinyi and Li, Zimeng and Chen, Xuhang and Wang, Zhen and Pun, Chi-Man},year={2024},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Auckland, New Zealand},doi={10.1007/978-981-96-6594-5_16},}
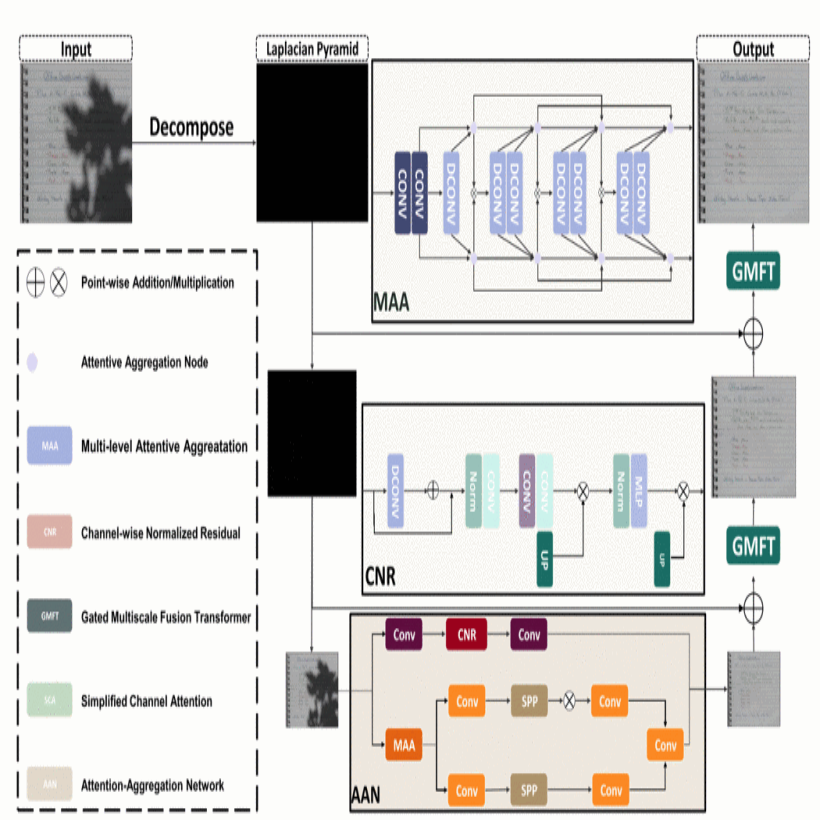
DocDeshadower: Frequency-Aware Transformer for Document Shadow Removal
Ziyang
Zhou*, Yingtie
Lei*
, Xuhang
Chen†, Shenghong
Luo
, Wenjun
Zhang, Chi-Man
Pun†
, and Zhen
Wang
In IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2024
Shadows in scanned documents pose significant challenges for document analysis and recognition tasks due to their negative impact on visual quality and readability. Current shadow removal techniques, including traditional methods and deep learning approaches, face limitations in handling varying shadow intensities and preserving document details. To address these issues, we propose DocDeshadower, a novel multi-frequency Transformer-based model built upon the Laplacian Pyramid. By decomposing the shadow image into multiple frequency bands and employing two critical modules: the Attention-Aggregation Network for low-frequency shadow removal and the Gated Multi-scale Fusion Transformer for global refinement. DocDeshadower effectively removes shadows at different scales while preserving document content. Extensive experiments demonstrate DocDe-shadower’s superior performance compared to state-of-the-art methods, highlighting its potential to significantly improve document shadow removal techniques. The code is available at https://github.com/leiyingtie/DocDeshadower.
@inproceedings{zhou2024docdeshadower,title={DocDeshadower: Frequency-Aware Transformer for Document Shadow Removal},author={Zhou, Ziyang and Lei, Yingtie and Chen, Xuhang and Luo, Shenghong and Zhang, Wenjun and Pun, Chi-Man and Wang, Zhen},year={2024},booktitle={IEEE International Conference on Systems, Man, and Cybernetics (SMC)},publisher={IEEE},address={Kuching, Malaysia},pages={2468--2473},doi={10.1109/SMC54092.2024.10831480},}
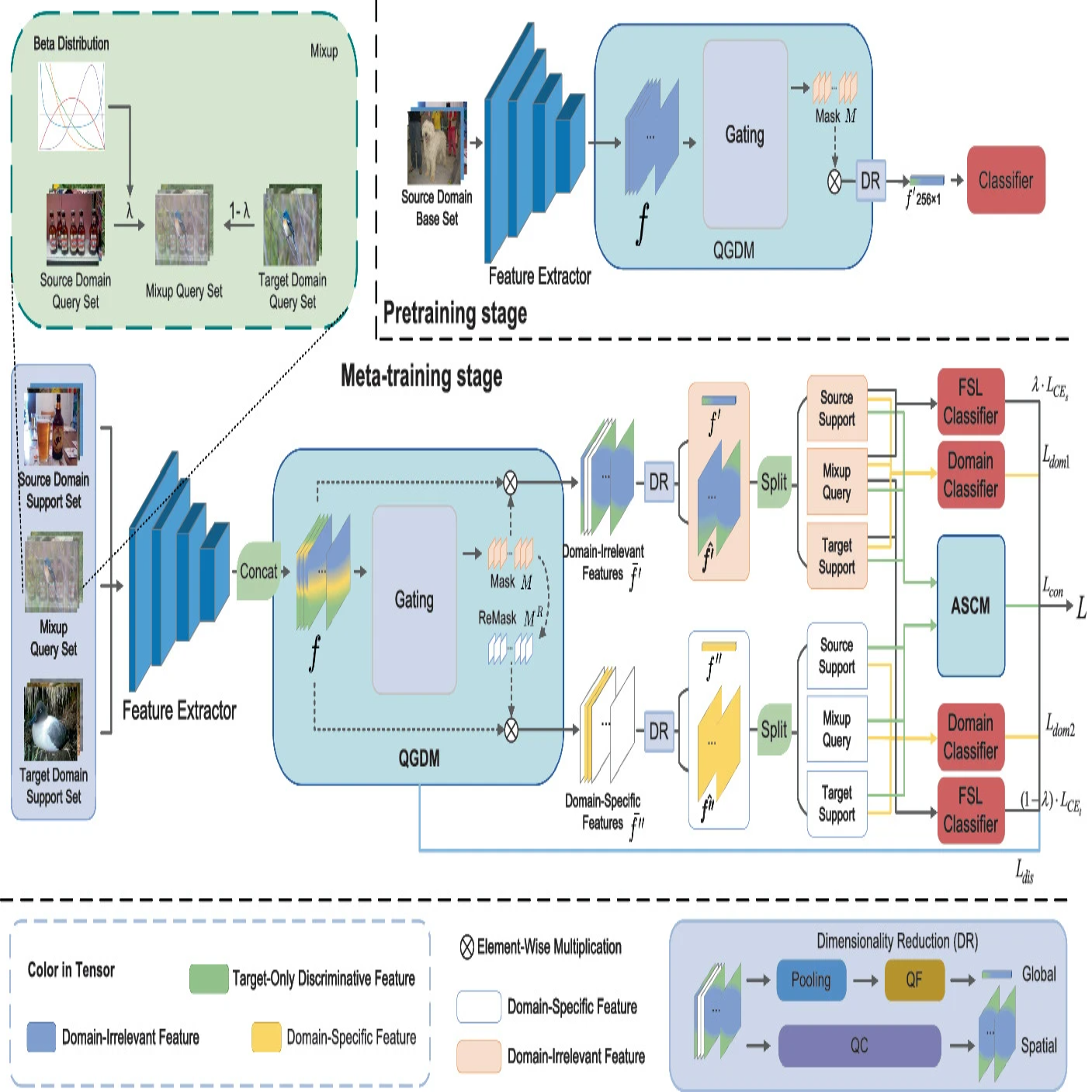
PDGC: Properly Disentangle by Gating and Contrasting for Cross-Domain Few-Shot Classification
A viable strategy for Cross-Domain Few-Shot Learning (CD-FSL) involves disentangling features into a domain-irrelevant part and a domain-specific part. The key to this strategy is how to make the model obtain more discriminative features in the target domain to keep accuracy and generalization in the few-shot setting. We propose the Properly Disentangle by Gating and Contrasting (PDGC) framework to accomplish this. It includes a Quaternion Gating Disentangle Module (QGDM) and an Attention-based Spatial Contrasting Module (ASCM). QGDM is utilized to delve deeper into the embedded inter-channel information and mitigate the inherent information loss during the disentangling process. Meanwhile, ASCM is utilized as a regularization constraint to avoid over-focusing on seen classes on CD-FSL problems leading to excessive disentangling and loss of generalization ability. Compared to the baseline, our method obtains an average of 2.3% and 3.68% improvement in 5-way 1-shot and 5-way 5-shot respectively in the FWT’s benchmark, and improves on most of the datasets in the BSCD-FSL’s benchmark.
@inproceedings{chen2024pdgc,title={PDGC: Properly Disentangle by Gating and Contrasting for Cross-Domain Few-Shot Classification},author={Chen, Yanjie and Huang, Guoheng and Yuan, Xiaochen and Chen, Xuhang and Li, Yan and Pun, Chi-Man and Quan, Junbing},year={2024},booktitle={Computer Graphics International Conference (CGI)},publisher={Springer},address={Geneva, Switzerland},pages={335--347},doi={10.1007/978-3-031-82021-2_24},}
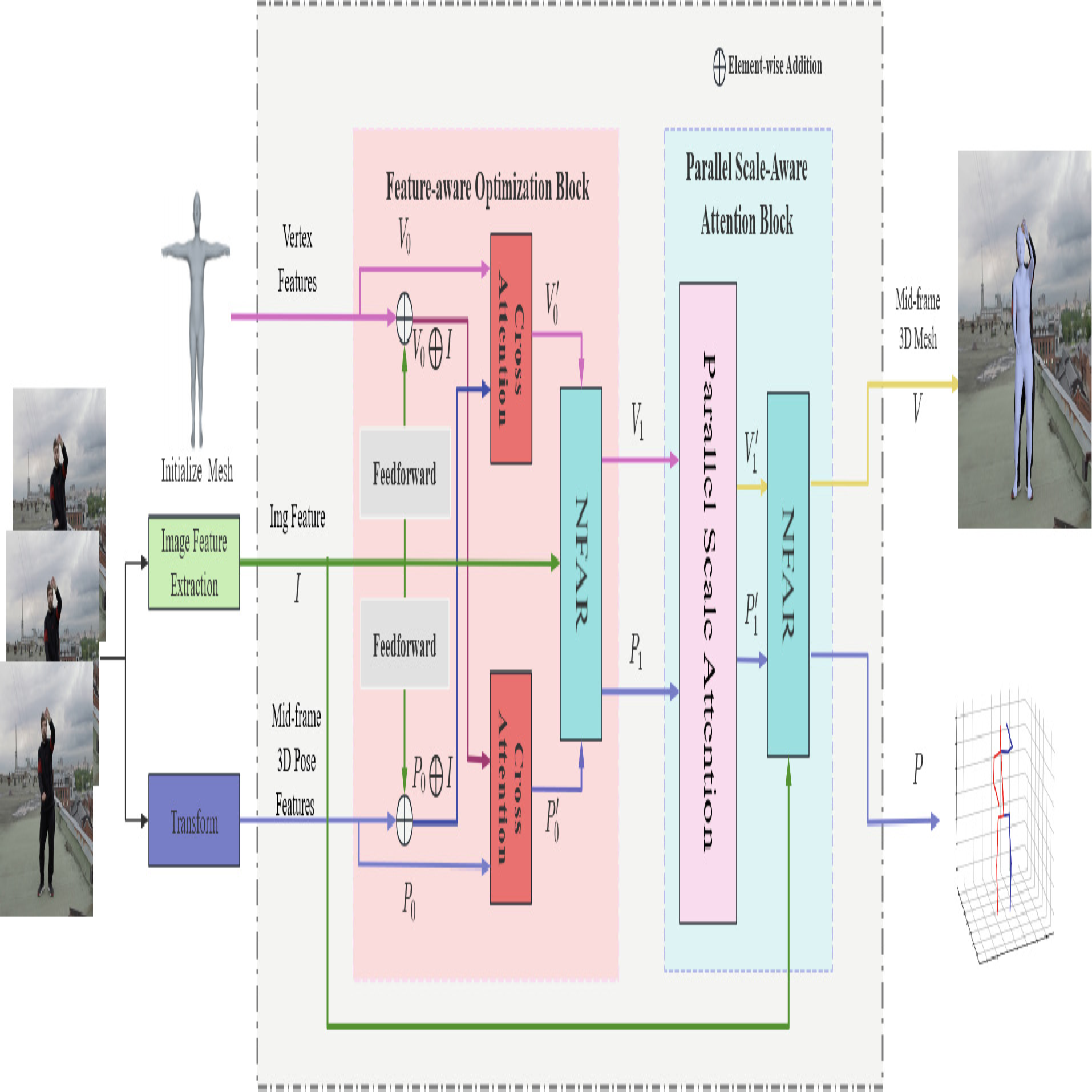
FOPS-V: Feature-Aware Optimization and Parallel Scale Fusion for 3D Human Reconstruction in Video
Video-based 3D human reconstruction, a fundamental task in computer vision, aims to accurately estimate the 3D pose and shape of the human body from video sequences. While recent methods leverage spatial and temporal feature extraction techniques, many remain limited by single-scale processing, hindering their performance in complex scenes. Additionally, challenges such as occlusion and complex poses often lead to inaccurate reconstructions. To address these limitations, we propose FOPS-V: Feature-aware Optimization and Parallel Scale Fusion for 3D Human Reconstruction in Video. Our approach comprises three key components: a Feature-Aware Optimization (FAO) block, a Parallel Scale-Aware Attention (PSAA) block, and a Normalized Feature-Aware Representation (NFAR) guided by Feature-Response Layer Normalization (FRLN). The FAO block enhances feature extraction by optimizing joint and mesh vertex representations through the fusion of image features and learned query vectors. The PSAA block performs subscale feature extraction for joint and mesh vertices and fuses multiscale feature information to improve pose and shape representations. Guided by FRLN, the NFAR addresses instability caused by variations in feature statistics within the FAO and PSAA blocks. This normalization, with an adaptable threshold, enhances robustness to noisy or outlier data, preventing performance degradation. Extensive evaluations on the 3DPW, MPI-INF-3DHP, and Human3.6M datasets demonstrate that FOPS-V outperforms state-of-the-art methods, highlighting its effectiveness for 3D human reconstruction in video.
@inproceedings{huang2024fops-v,title={FOPS-V: Feature-Aware Optimization and Parallel Scale Fusion for 3D Human Reconstruction in Video},author={Huang, Yang and Huang, Guoheng and Cheng, Lianglun and Huo, Yejing and Chen, Xuhang and Yuan, Xiaochen and Zhong, Guo and Pun, Chi-Man},year={2024},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Auckland, New Zealand},pages={180--194},doi={10.1007/978-981-96-6596-9_13},}
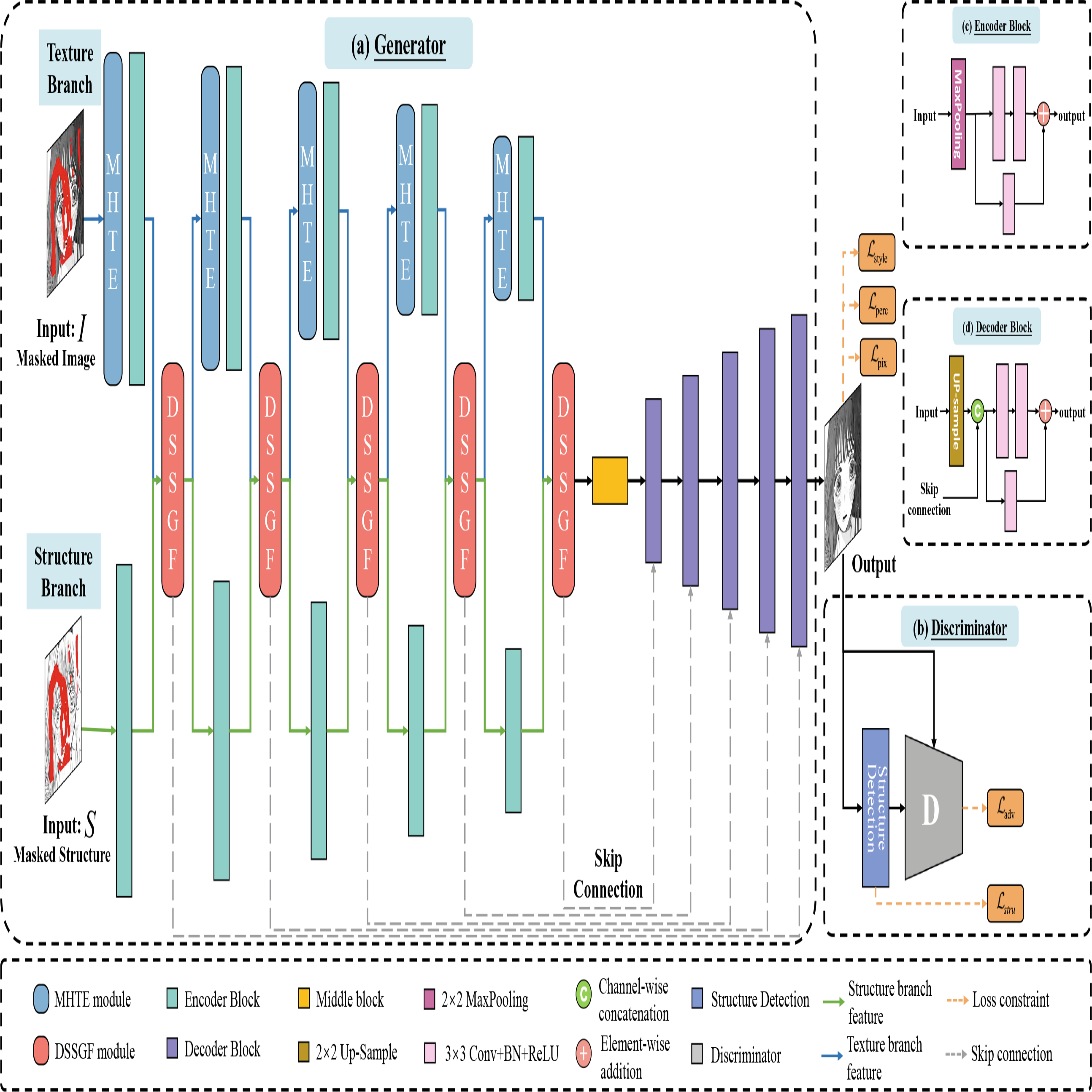
Advancing Comic Image Inpainting: A Novel Dual-Stream Fusion Approach with Texture Enhancements
In the process of comic localization, a crucial step is to fill in the pixels obscured due to the removal of dialogue boxes or sound effect text. Comic inpainting is more challenging than natural images. On one hand, its structure and texture are highly abstract, which confuses semantic interpretation and content synthesis. On the other hand, high-frequency information specific to comic images (such as lines and dots) is crucial for visual representation. This paper proposes the Texture-Structure Fusion Network (TSF-Net) with dual-stream encoder, introducing the Dual-stream Space-Gated Fusion (DSSGF) module for effective feature interaction. Additionally, a Multi-scale Histogram Texture Enhancement (MHTE) module is designed to enhance texture information aggregation dynamically. Visual comparisons and quantitative experiments demonstrate the effectiveness of the method, proving its superiority over existing techniques in comic inpainting. The implementation methods and dataset can be obtained from https://github.com/arashi-knight/comic-inpaint-pre.
@inproceedings{hong2024advancing,title={Advancing Comic Image Inpainting: A Novel Dual-Stream Fusion Approach with Texture Enhancements},author={Hong, Zilan and Cheng, Lianglun and Huang, Guoheng and Chen, Xuhang and Pun, Chi-Man and Yuan, Xiaochen and Zhong, Guo},year={2024},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Auckland, New Zealand},pages={181--195},doi={10.1007/978-981-96-6969-1_13},}
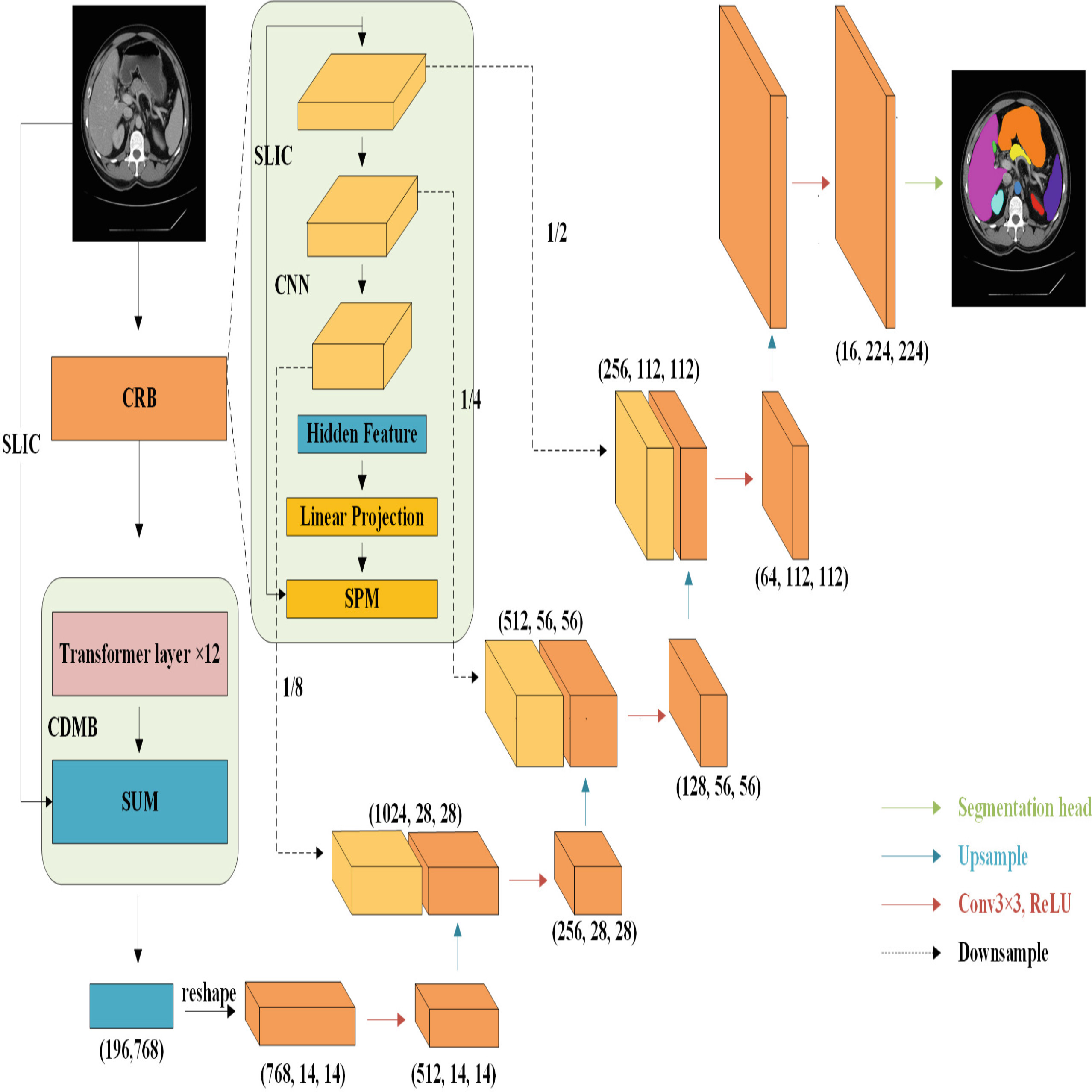
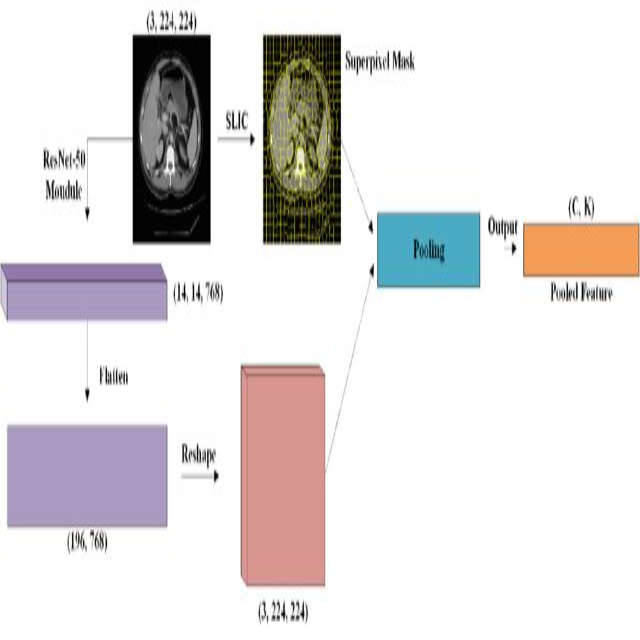
RST-UNet: Medical Image Segmentation Transformer Effectively Combining Superpixel
Medical image segmentation has advanced with models like UCTransNet, TransUNet, and TransClaw U-Net, which integrate Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). However, these models face limitations due to the locality of convolutions and the computational demands of Transformers. To overcome these challenges, we introduce RST-UNet, an innovative encoder-decoder network that balances effectiveness with computational efficiency. RST-UNet features two groundbreaking innovations: the Compact Representation Block (CRB) and the Compact Dependency Modeling Block (CDMB). The CRB utilizes superpixel pooling to capture long-range dependencies while minimizing parameters and computation time. The CDMB integrates superpixel unpooling with attention mechanisms and Rotary Position Embedding (RoPE) to enhance long-range dependency modeling. This approach emphasizes critical regions and leverages RoPE to capture extensive image dependencies effectively. Our experimental results on publicly available synapse datasets highlight RST-UNet’s exceptional performance, particularly in segmenting small organs such as the gallbladder, right kidney, and pancreas. Remarkably, RST-UNet achieves superior results without pre-training, showcasing its high adaptability for diverse medical image segmentation tasks. This work represents a significant advancement in developing efficient and effective algorithms for medical image analysis.
@inproceedings{ye2024rst-unet,title={RST-UNet: Medical Image Segmentation Transformer Effectively Combining Superpixel},author={Ye, Songhang and Feng, Zhoule and Huang, Guoheng and Ke, Jinghong and Chen, Xuhang and Pun, Chi-Man and Zhong, Guo and Yuan, Xiaochen},year={2024},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Auckland, New Zealand},pages={336--350},doi={10.1007/978-981-96-6969-1_23},}
ROSAL: Semi-supervised Active Learning with Representation Aggregation and Outlier for Endoscopy Image Classification
The classification of endoscopy images is vital for earlydetection and prevention of Colorectal Cancer (CRC). However, manual annotation of these images is expensive. Semi-supervised ActiveLearning (SAL) can help reduce costs, but issues with the accuracyof pseudo-labels and the tendency to over-select outliers remain. Toaddress these, we introduce ROSAL, a new SAL framework featuringRepresentational Correlation-based Pseudo-label Training (RCPT) andOutlier-based Hybrid Querying (OHQ). RCPT employs a pseudo-labelcontrastive loss to enhance agreement among unlabeled data representations and reduce discord. The pseudo-label generator in RCPT leveragesthis correlation for more precise labeling. OHQ introduces a distancefactor to minimize outlier selection through a hybrid querying strategy. Experimental results demonstrate that ROSAL outperforms otheractive learning methods, achieving 71.46% and 90.79% accuracy on apublicly available endoscopic dataset and a publicly available naturalimage dataset, respectively, using only 40% and 20% of the labeled data.
@inproceedings{huang2024rosal,title={ROSAL: Semi-supervised Active Learning with Representation Aggregation and Outlier for Endoscopy Image Classification},author={Huang, Xiaocong and Huang, Guoheng and Zhong, Guo and Yuan, Xiaochen and Chen, Xuhang and Pun, Chi-Man and Chen, Jianwu},year={2024},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Auckland, New Zealand},pages={350--364},doi={10.1007/978-981-96-6606-5_24},}
MMCIE: Multi-order Multivariate Coalition Internal-External Interaction for Image Explanation
Shapley values are extensively utilized in Explainable Artificial Intelligence to interpret predictions made by complex machine learning models. However, much of the research has focused on addressing the costly computational aspects of Shapley values, neglecting the rich interactive knowledge representation inherent in the data within the model. Therefore, MMCIE is proposed in this article, focusing on exploring the conceptual modeling of data by the model. Based on Shapley values, it defines the interaction between inner and outer coalitions to accurately quantify the concept of model modeling. Specifically, the Superpixel Coalitions Selecting Module (SCSM) is proposed, which defines coalitions as entities and paves the way for calculating multivariable interaction values and internal interaction values. Additionally, the Internal and External Interaction Module (IEIM) acts as a bridge, computing and connecting the internal and external interaction values of coalitions, thereby constructing the feature prototype of the model. Moreover, the Multi-order Equidistance Coalitions Modeling Module (MECMM) is introduced as an effective approach to reduce computational complexity and explore the storage methods of the model’s conceptual modeling. Experiments on two datasets show the advantage of MMCIE over existing methods, revealing the model’s concept modeling process through multi-order interactions and offering a fresh view for model interpretation.
@inproceedings{huang2024mmcie,title={MMCIE: Multi-order Multivariate Coalition Internal-External Interaction for Image Explanation},author={Huang, Mingfeng and Huang, Guoheng and Zhou, Xiaomin and Pun, Chi-Man and Chen, Xuhang and Yuan, Xiaochen and Zhong, Guo},year={2024},booktitle={International Conference on Neural Information Processing (ICONIP)},publisher={Springer},address={Auckland, New Zealand},pages={1--15},doi={10.1007/978-981-96-6948-6_1},editor={Mahmud, Mufti and Doborjeh, Maryam and Wong, Kevin and Leung, Andrew Chi Sing and Doborjeh, Zohreh and Tanveer, M.},}
Shadow removal improves the visual quality and legibility of digital copies of documents. However, document shadow removal remains an unresolved subject. Traditional techniques rely on heuristics that vary from situation to situation. Given the quality and quantity of current public datasets, the majority of neural network models are ill-equipped for this task. In this paper, we propose a Transformer-based model for document shadow removal that utilizes shadow context encoding and decoding in both shadow and shadow-free regions. Additionally, shadow detection and pixel-level enhancement are included in the whole coarse-to-fine process. On the basis of comprehensive benchmark evaluations, it is competitive with state-of-the-art methods.
@inproceedings{chen2023shadocnet,title={Shadocnet: Learning Spatial-Aware Tokens in Transformer for Document Shadow Removal},author={Chen, Xuhang and Cun, Xiaodong and Pun, Chi-Man and Wang, Shuqiang},year={2023},booktitle={Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},publisher={IEEE},address={Rhodes Island, Greece},pages={1--5},doi={10.1109/ICASSP49357.2023.10095403},}
Film, a classic image style, is culturally significant to the whole photographic industry since it marks the birth of photography. However, film photography is time-consuming and expensive, necessitating a more efficient method for collecting film-style photographs. Numerous datasets that have emerged in the field of image enhancement so far are not film-specific. In order to facilitate film-based image stylization research, we construct FilmSet, a large-scale and high-quality film style dataset. Our dataset includes three different film types and more than 5000 in-the-wild high resolution images. Inspired by the features of FilmSet images, we propose a novel framework called FilmNet based on Laplacian Pyramid for stylizing images across frequency bands and achieving film style outcomes. Experiments reveal that the performance of our model is superior than state-of-the-art techniques. The link of our dataset and code is https://github.com/CXH-Research/FilmNet.
@inproceedings{li2023large-scale,title={A Large-Scale Film Style Dataset for Learning Multi-frequency Driven Film Enhancement},author={Li, Zinuo and Chen, Xuhang and Wang, Shuqiang and Pun, Chi-Man},year={2023},booktitle={Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI)},publisher={International Joint Conferences on Artificial Intelligence Organization},address={Macao, China},pages={1160--1168},doi={10.24963/IJCAI.2023/129},}
Shadows often occur when we capture the documents with casual equipment, which influences the visual quality and readability of the digital copies. Different from the algorithms for natural shadow removal, the algorithms in document shadow removal need to preserve the details of fonts and figures in high-resolution input. Previous works ignore this problem and remove the shadows via approximate attention and small datasets, which might not work in real-world situations. We handle high-resolution document shadow removal directly via a larger-scale real-world dataset and a carefully designed frequency-aware network. As for the dataset, we acquire over 7k couples of high-resolution (2462 x 3699) images of real-world document pairs with various samples under different lighting circumstances, which is 10 times larger than existing datasets. As for the design of the network, we decouple the high-resolution images in the frequency domain, where the low-frequency details and high-frequency boundaries can be effectively learned via the carefully designed network structure. Powered by our network and dataset, the proposed method clearly shows a better performance than previous methods in terms of visual quality and numerical results. The code, models, and dataset are available at https://github.com/CXH-Research/DocShadow-SD7K.
@inproceedings{li2023high-resolution,title={High-Resolution Document Shadow Removal via A Large-Scale Real-World Dataset and A Frequency-Aware Shadow Erasing Net},author={Li, Zinuo and Chen, Xuhang and Pun, Chi-Man and Cun, Xiaodong},year={2023},booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},publisher={IEEE},address={Paris, France},pages={12449--12458},doi={10.1109/ICCV51070.2023.01144},}
Brain network analysis is essential for diagnosing and intervention for Alzheimer’s disease (AD). However, previous research relied primarily on specific time-consuming and subjective toolkits. Only few tools can obtain the structural brain networks from brain diffusion tensor images (DTI). In this paper, we propose a diffusion based end-to-end brain network generative model Brain Diffuser that directly shapes the structural brain networks from DTI. Compared to existing toolkits, Brain Diffuser exploits more structural connectivity features and disease-related information by analyzing disparities in structural brain networks across subjects. For the case of Alzheimer’s disease, the proposed model performs better than the results from existing toolkits on the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database.
@inproceedings{chen2023brain,title={Brain Diffuser: An End-to-End Brain Image to Brain Network Pipeline},author={Chen, Xuhang and Lei, Baiying and Pun, Chi-Man and Wang, Shuqiang},year={2023},booktitle={Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV)},publisher={Springer},address={Xiamen, China},pages={16--26},doi={10.1007/978-981-99-8558-6_2},}
MR Image Super-Resolution Using Wavelet Diffusion for Predicting Alzheimer’s Disease
Alzheimer’s disease (AD) is a neurodegenerative disorder that exerts a substantial influence on individuals worldwide. Magnetic resonance imaging (MRI) can detect and track disease progression. However, the majority of MRI data currently available is characterized by low resolution. The present study introduces a novel approach for MRI super-resolution by integrating diffusion model with wavelet decomposition techniques. The methodology proposed in this study is tailored to address the issue of restricted data availability. It utilizes adversarial training and capitalizes on the advantages of denoising diffusion probabilistic model (DDPM), while simultaneously avoiding the problem of diversity collapse. The proposed method incorporates wavelet decomposition within the latent space to augment the resilience and efficiency of generative models. The experimental findings demonstrate the superior efficacy of our proposed model in contrast to alternative techniques, as indicated by the SSIM and FID metrics. Moreover, our methodology has the potential to enhance the precision of Alzheimer’s disease assessment.
@inproceedings{huang2023mr,title={MR Image Super-Resolution Using Wavelet Diffusion for Predicting Alzheimer's Disease},author={Huang, Guoli and Chen, Xuhang and Shen, Yanyan and Wang, Shuqiang},year={2023},booktitle={International Conference on Brain Informatics (BI)},publisher={Springer},address={Hoboken, NJ, USA},pages={146--157},doi={10.1007/978-3-031-43075-6_13},}
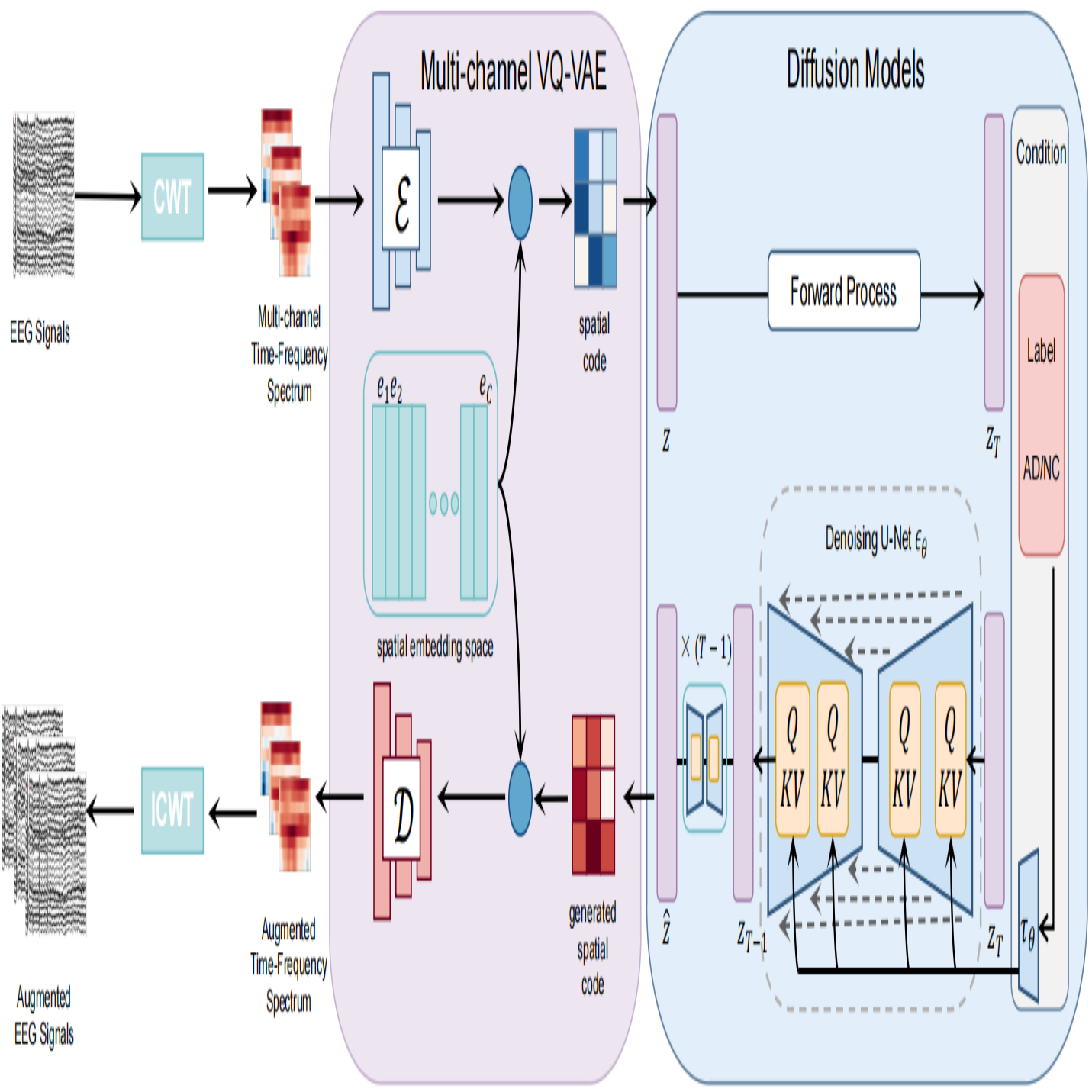
Generative AI Enables EEG Data Augmentation for Alzheimer’s Disease Detection Via Diffusion Model
Electroencephalography (EEG) is a non-invasive method to measure the electrical activity of the brain and can be regarded as an effective means of diagnosing Alzheimer’s disease (AD). However, The diagnosis of AD based on EEG often encounters the problem of data scarcity. For deep learning models, data scarcity problems lead to overfitting of the model, making it impossible to build effective, highly accurate, and stable models. Data augmentation is often used as an effective means to solve the problem of data scarcity. In this paper, we propose a diffusion models-based EEG data augmentation framework (Diff-EEG). The proposed framework Vector Quantized Variational autoencoders(VQ-VAE) and guided diffusion models to learn the distribution of limited EEG dataset, thereby generating high-quality artificially synthesized EEG data to supplement the dataset. Finally, the result of experiments demonstrate that our proposed method can generate high-quality artificial EEG data, which can effectively improve the performance of AD diagnosis models.
@inproceedings{zhou2023generative,title={Generative AI Enables EEG Data Augmentation for Alzheimer's Disease Detection Via Diffusion Model},author={Zhou, Tong and Chen, Xuhang and Shen, Yanyan and Nieuwoudt, Martin and Pun, Chi-Man and Wang, Shuqiang},year={2023},booktitle={IEEE International Symposium on Product Compliance Engineering-Asia (ISPCE-ASIA)},publisher={IEEE},address={Shanghai, China},pages={1--6},doi={10.1109/ISPCE-ASIA60405.2023.10365931},}
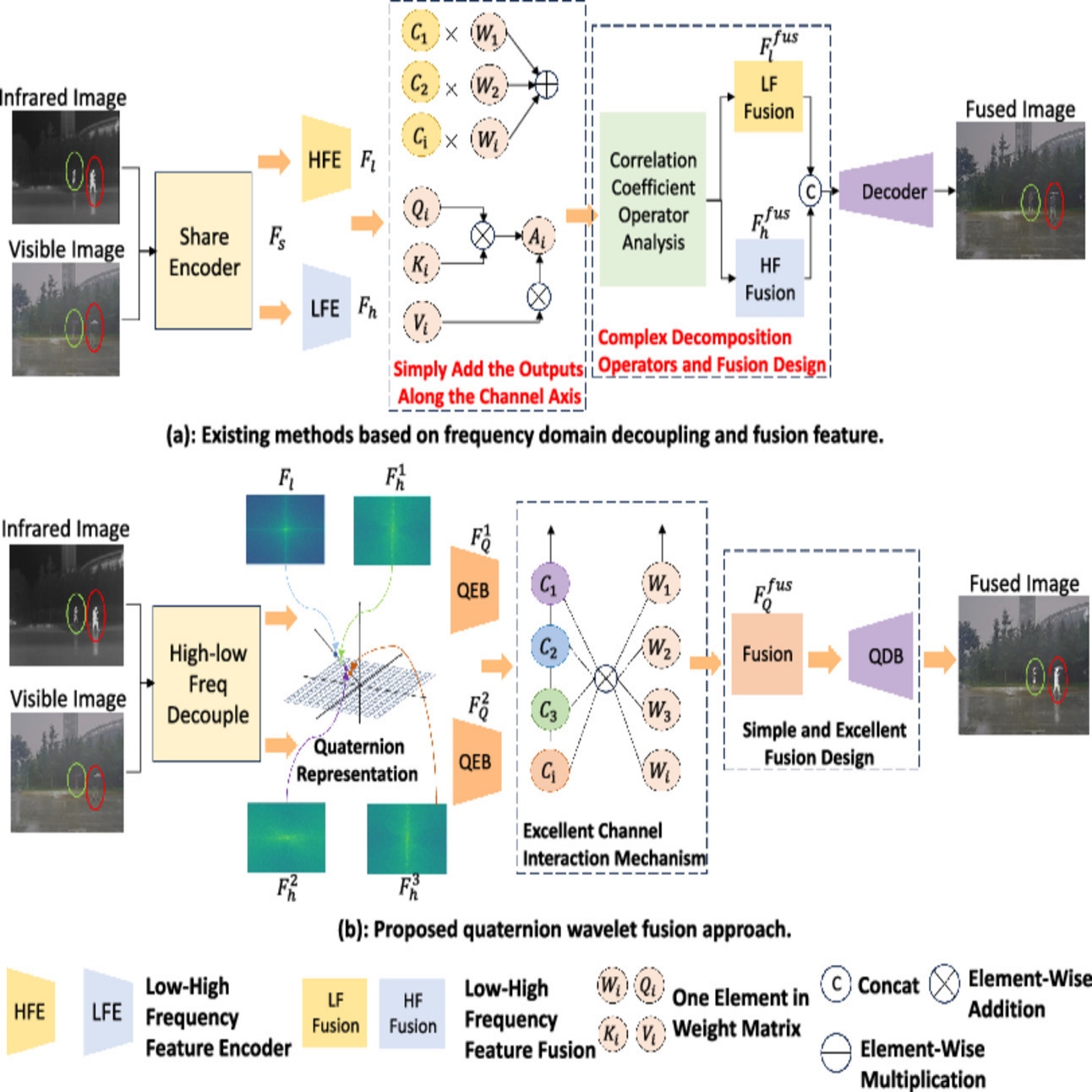
Multi-modal Image Fusion (MMIF) enhances visual tasks by combining the strengths of different image modalities to improve object visibility and texture details. However, existing methods face two major challenges: First, a lack of intrinsic frequency-domain awareness, relying heavily on complex filters and fusion techniques that can be less adaptive. Second, simplistic channel combination that overlooks essential complex inter-channel relationships. To address these issues, we propose QWNet, a novel Quaternion Wavelet Network that harnesses both spatial and frequency information to enhance the network’s inductive bias towards local features. By integrating wavelet transforms, we decompose input modalities into high- and low-frequency components, capturing global structures and fine details. These components are represented as quaternions, enabling the network to model complex inter-channel dependencies often missed by traditional real-valued networks. We also introduce a Bidirectional Adaptive Attention Module (BAAM) for effective multi-modal information interaction and difference enhancement, and a Quaternion Cross-modal Fusion Module (QCFM) to strengthen inter-channel relationships and effectively combine key features from different modalities. Extensive experiments confirm that our QWNet outperforms existing methods in fusion quality and downstream tasks like semantic segmentation, using only 4.27 K parameters and a computational cost of 0.30G FLOPs. The source code will be available at https://github.com/Mrzhans/QWNet.
@article{yang2025qwnet,title={QWNet: A Quaternion Wavelet Network for Spatial-Frequency Aware multi-modal Image Fusion},author={Yang, Jietao and Lin, Miaoshan and Huang, Guoheng and Chen, Xuhang and Zhang, Xiaofeng and Yuan, Xiaochen and Pun, Chi-Man and Ling, Bingo Wing-Kuen},year={2026},journal={Neural Networks},volume={196},pages={108364},doi={j.neunet.2025.108364},publisher={Elsevier},}
2025
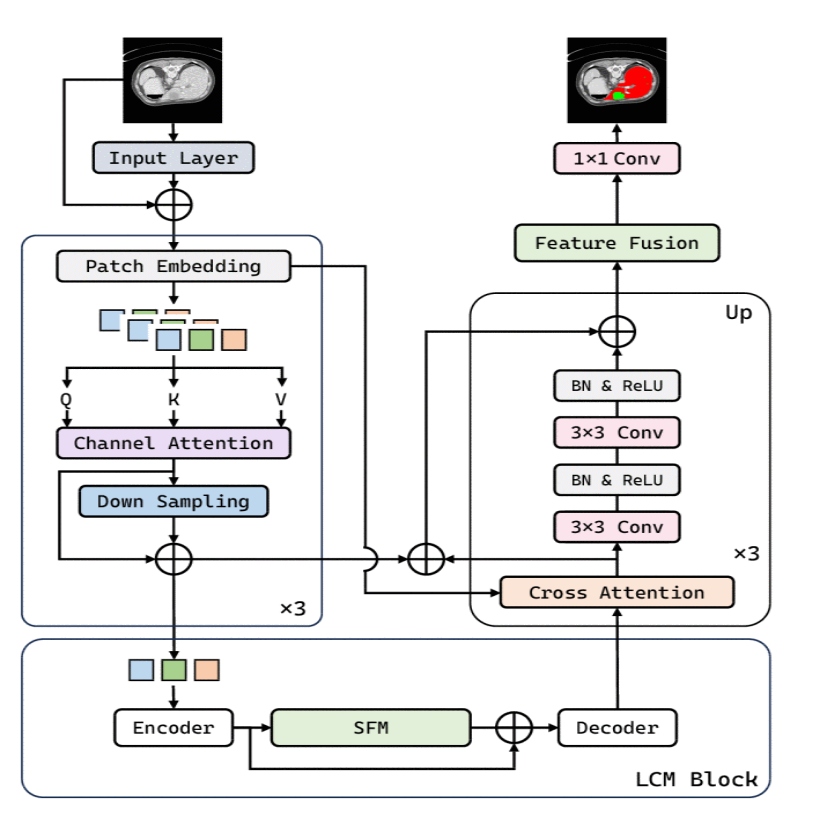
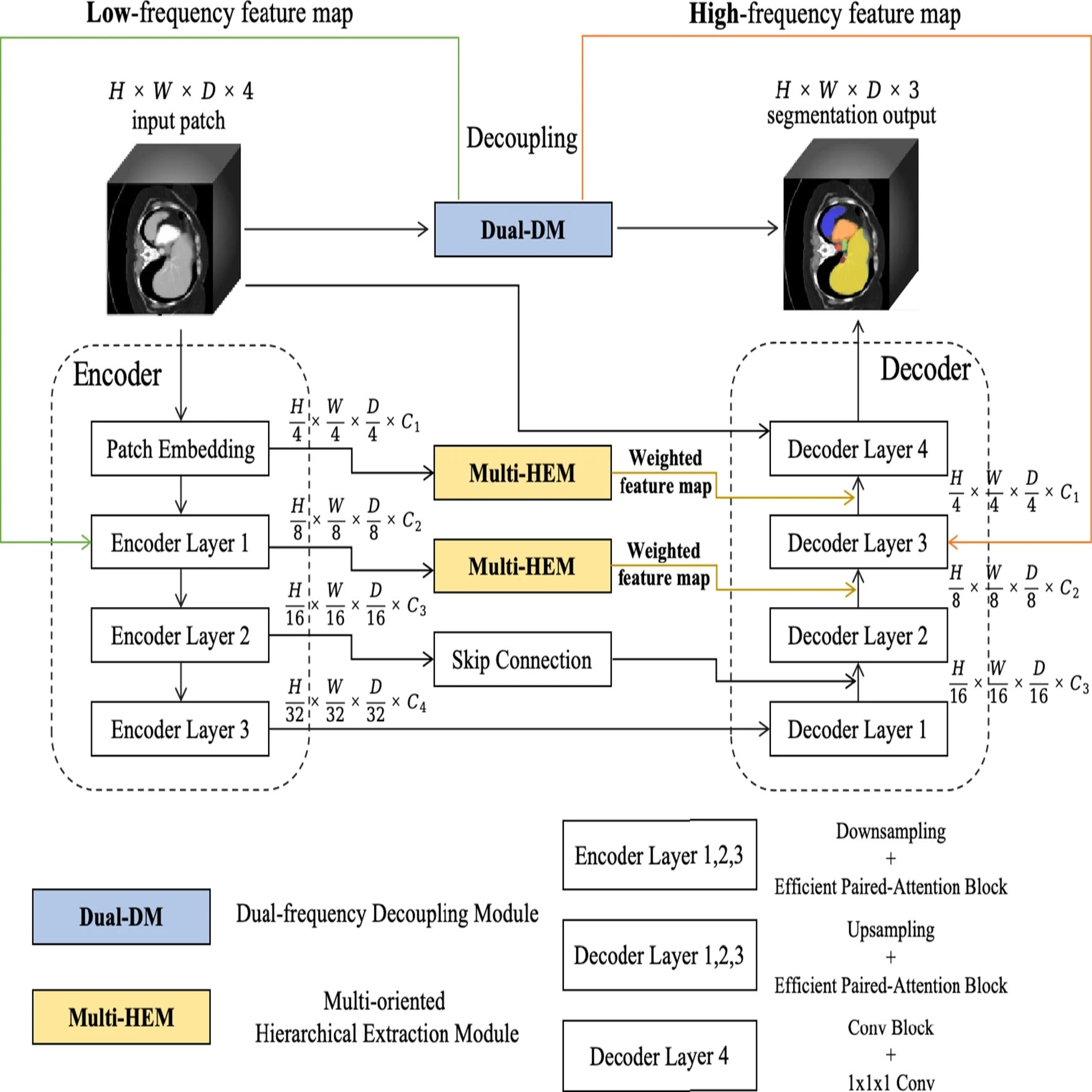
HEDN: multi-oriented hierarchical extraction and dual-frequency decoupling network for 3D medical image segmentation
Yu
Wang, Guoheng
Huang†, Zeng
Lu
, Ying
Wang
, Xuhang
Chen, Xiaochen
Yuan
, Yan
Li†, Liujie
Ni†
, and Yingping
Huang†
Medical & Biological Engineering & Computing, 2025
Previous 3D encoder-decoder segmentation architectures struggled with fine-grained feature decomposition, resulting in unclear feature hierarchies when fused across layers. Furthermore, the blurred nature of contour boundaries in medical imaging limits the focus on high-frequency contour features. To address these challenges, we propose a Multi-oriented Hierarchical Extraction and Dual-frequency Decoupling Network (HEDN), which consists of three modules: Encoder-Decoder Module (E-DM), Multi-oriented Hierarchical Extraction Module (Multi-HEM), and Dual-frequency Decoupling Module (Dual-DM). The E-DM performs the basic encoding and decoding tasks, while Multi-HEM decomposes and fuses spatial and slice-level features in 3D, enriching the feature hierarchy by weighting them through 3D fusion. Dual-DM separates high-frequency features from the reconstructed network using self-supervision. Finally, the self-supervised high-frequency features separated by Dual-DM are inserted into the process following Multi-HEM, enhancing interactions and complementarities between contour features and hierarchical features, thereby mutually reinforcing both aspects. On the Synapse dataset, HEDN outperforms existing methods, boosting Dice Similarity Score (DSC) by 1.38% and decreasing 95% Hausdorff Distance (HD95) by 1.03 mm. Likewise, on the Automatic Cardiac Diagnosis Challenge (ACDC) dataset, HEDN achieves 0.5% performance gains across all categories.
@article{wang2025hedn,title={HEDN: multi-oriented hierarchical extraction and dual-frequency decoupling network for 3D medical image segmentation},author={Wang, Yu and Huang, Guoheng and Lu, Zeng and Wang, Ying and Chen, Xuhang and Yuan, Xiaochen and Li, Yan and Ni, Liujie and Huang, Yingping},year={2025},journal={Medical {\&} Biological Engineering {\&} Computing},publisher={Springer},volume={63},number={1},pages={267--291},doi={10.1007/s11517-024-03192-y},}
A comprehensive survey on shadow removal from document images: datasets, methods, and opportunities
Bingshu
Wang
, Changping
Li†, Wenbin
Zou
, Yongjun
Zhang
, Xuhang
Chen
, and C.l. Philip
Chen
With the rapid development of document digitization, people have become accustomed to capturing and processing documents using electronic devices such as smartphones. However, the captured document images often suffer from issues like shadows and noise due to environmental factors, which can affect their readability. To improve the quality of captured document images, researchers have proposed a series of models or frameworks and applied them in distinct scenarios such as image enhancement, and document information extraction. In this paper, we primarily focus on shadow removal methods and open-source datasets. We concentrate on recent advancements in this area, first organizing and analyzing nine available datasets. Then, the methods are categorized into conventional methods and neural network-based methods. Conventional methods use manually designed features and include shadow map-based approaches and illumination-based approaches. Neural network-based methods automatically generate features from data and are divided into single-stage approaches and multi-stage approaches. We detail representative algorithms and briefly describe some typical techniques. Finally, we analyze and discuss experimental results, identifying the limitations of datasets and methods. Future research directions are discussed, and nine suggestions for shadow removal from document images are proposed. To our knowledge, this is the first survey of shadow removal methods and related datasets from document images.
@article{wang2025comprehensive,title={A comprehensive survey on shadow removal from document images: datasets, methods, and opportunities},author={Wang, Bingshu and Li, Changping and Zou, Wenbin and Zhang, Yongjun and Chen, Xuhang and Chen, C.l. Philip},year={2025},journal={Vicinagearth},publisher={Springer},volume={2},number={1},doi={10.1007/s44336-024-00010-9},}
Qean: quaternion-enhanced attention network for visual dance generation
Zhizhen
Zhou, Yejing
Huo, Guoheng
Huang†, An
Zeng
, Xuhang
Chen†
, Lian
Huang, and Zinuo
Li
The study of music-generated dance is a novel and challenging image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time-series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a quaternion-enhanced attention network for visual dance synthesis from a quaternion perspective, which consists of a spin position embedding (SPE) module and a quaternion rotary attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset, respectively.
@article{zhou2025qean,title={Qean: quaternion-enhanced attention network for visual dance generation},author={Zhou, Zhizhen and Huo, Yejing and Huang, Guoheng and Zeng, An and Chen, Xuhang and Huang, Lian and Li, Zinuo},year={2025},journal={The Visual Computer},publisher={Springer},volume={41},number={2},pages={961--973},doi={10.1007/s00371-024-03376-5},}
Weakly supervised semantic segmentation via saliency perception with uncertainty-guided noise suppression
Weakly Supervised Semantic Segmentation (WSSS) has become increasingly popular for achieving remarkable segmentation with only image-level labels. Current WSSS approaches extract Class Activation Mapping (CAM) from classification models to produce pseudo-masks for segmentation supervision. However, due to the gap between image-level supervised classification loss and pixel-level CAM generation tasks, the model tends to activate discriminative regions at the image level rather than pursuing pixel-level classification results. Moreover, insufficient supervision leads to unrestricted attention diffusion in the model, further introducing inter-class recognition noise. In this paper, we introduce a framework that employs Saliency Perception and Uncertainty, which includes a Saliency Perception Module (SPM) with Pixel-wise Transfer Loss (SP-PT), and an Uncertainty-guided Noise Suppression method. Specifically, within the SPM, we employ a hybrid attention mechanism to expand the receptive field of the module and enhance its ability to perceive salient object features. Meanwhile, a Pixel-wise Transfer Loss is designed to guide the attention diffusion of the classification model to non-discriminative regions at the pixel-level, thereby mitigating the bias of the model. To further enhance the robustness of CAM for obtaining more accurate pseudo-masks, we propose a noise suppression method based on uncertainty estimation, which applies a confidence matrix to the loss function to suppress the propagation of erroneous information and correct it, thus making the model more robust to noise. We conducted experiments on the PASCAL VOC 2012 and MS COCO 2014, and the experimental results demonstrate the effectiveness of our proposed framework. Code is available at https://github.com/pur-suit/SPU.
@article{liu2025weakly,title={Weakly supervised semantic segmentation via saliency perception with uncertainty-guided noise suppression},author={Liu, Xinyi and Huang, Guoheng and Yuan, Xiaochen and Zheng, Zewen and Zhong, Guo and Chen, Xuhang and Pun, Chi-Man},year={2025},journal={The Visual Computer},publisher={Springer},volume={41},number={4},pages={2891--2906},doi={10.1007/S00371-024-03574-1},}
Psanet: prototype-guided salient attention for few-shot segmentation
Few-shot semantic segmentation aims to learn a generalized model for unseen-class segmentation with just a few densely annotated samples. Most current metric-based prototype learning models utilize prototypes to assist in query sample segmentation by directly utilizing support samples through Masked Average Pooling. However, these methods frequently fail to consider the semantic ambiguity of prototypes, the limitations in performance when dealing with extreme variations in objects, and the semantic similarities between different classes. In this paper, we introduce a novel network architecture named Prototype-guided Salient Attention Network (PSANet). Specifically, we employ prototype-guided attention to learn salient regions, allocating different attention weights to features at different spatial locations of the target to enhance the significance of salient regions within the prototype. In order to mitigate the impact of external distractor categories on the prototype, our proposed contrastive loss has the capability to acquire a more discriminative prototype to promote inter-class feature separation and intra-class feature compactness. Moreover, we suggest implementing a refinement operation for the multi-scale module in order to enhance the ability to capture complete contextual information regarding features at various scales. The effectiveness of our strategy is demonstrated by extensive tests performed on the PASCAL-5i and COCO-20i datasets, despite its inherent simplicity. Our code is available at https://github.com/woaixuexixuexi/PSANet.
@article{li2025psanet,title={Psanet: prototype-guided salient attention for few-shot segmentation},author={Li, Hao and Huang, Guoheng and Yuan, Xiaochen and Zheng, Zewen and Chen, Xuhang and Zhong, Guo and Pun, Chi-Man},year={2025},journal={The Visual Computer},publisher={Springer},volume={41},number={4},pages={2987--3001},doi={10.1007/S00371-024-03582-1},}
GRE2-MDCL: Graph Representation Embedding Enhanced via Multidimensional Contrastive Learning
Quanjun
Li
, Weixuan
Li
, Xiya
Zheng, Junhua
Zhou
, Wenming
Zhong
, Xuhang
Chen, and Chao
Long†
Graph representation learning aims to preserve graph topology when mapping nodes to vector representations, enabling downstream tasks like node classification and community detection. However, most graph neural network models require extensive labelled data, limiting their practical applicability. To address this, researchers have explored Graph Contrastive Learning (GCL), which uses enhanced graph data and contrastive learning to better capture graph structure and features, providing new avenues for solving real-world problems with limited labelled data. Building on this, this work proposes Graph Representation Embedding Enhanced via Multidimensional Contrastive Learning (GRE2-MDCL). GRE2-MDCL first globally and locally augments the input graph using SVD and LAGNN. The enhanced data is then fed into a triple network with a multi-head attention GNN as the core model. Finally, GRE2-MDCL constructs a multidimensional contrastive loss, incorporating cross-network, cross-view, and neighbor contrast, to optimize the model. Evaluated on Cora, Citeseer, and PubMed, GRE2-MDCL achieves average accuracies of 83.1%, 72.6%, and 82.7%, outperforming baseline GCL models. Visualizations also show tighter intra-cluster aggregation and clearer inter-cluster boundaries, demonstrating the framework’s effectiveness in improving upon the baseline.
@article{li2025gre2-mdcl,title={GRE2-MDCL: Graph Representation Embedding Enhanced via Multidimensional Contrastive Learning},author={Li, Quanjun and Li, Weixuan and Zheng, Xiya and Zhou, Junhua and Zhong, Wenming and Chen, Xuhang and Long, Chao},year={2025},journal={IEEE Access},publisher={IEEE},volume={13},pages={61312--61321},doi={10.1109/ACCESS.2025.3553862},}
Underwater imaging grapples with challenges from light-water interactions, leading to color distortions and reduced clarity. In response to these challenges, we propose a novel Color Balance Prior Guided Hybrid Sense Underwater Image Restoration framework (GuidedHybSensUIR). This framework operates on multiple scales, employing the proposed Detail Restorer module to restore low-level detailed features at finer scales and utilizing the proposed Feature Contextualizer module to capture long-range contextual relations of high-level general features at a broader scale. The hybridization of these different scales of sensing results effectively addresses color casts and restores blurry details. In order to effectively point out the evolutionary direction for the model, we propose a novel Color Balance Prior as a strong guide in the feature contextualization step and as a weak guide in the final decoding phase. We construct a comprehensive benchmark using paired training data from three real-world underwater datasets and evaluate on six test sets, including three paired and three unpaired, sourced from four real-world underwater datasets. Subsequently, we tested 14 traditional and retrained 23 deep learning existing underwater image restoration methods on this benchmark, obtaining metric results for each approach. This effort aims to furnish a valuable benchmarking dataset for standard basis for comparison. The extensive experiment results demonstrate that our method outperforms 37 other state-of-the-art methods overall on various benchmark datasets and metrics, despite not achieving the best results in certain individual cases. The code and dataset are available at https://github.com/CXH-Research/GuidedHybSensUIR.
@article{guo2025underwater2,title={Underwater Image Restoration Through a Prior Guided Hybrid Sense Approach and Extensive Benchmark Analysis},author={Guo, Xiaojiao and Chen, Xuhang and Wang, Shuqiang and Pun, Chi-Man},year={2025},journal={IEEE Transactions on Circuits and Systems for Video Technology},publisher={IEEE},volume={35},number={5},pages={4784--4800},doi={10.1109/TCSVT.2025.3525593},}
TCIA: A Transformer-CNN Model With Illumination Adaptation for Enhancing Cell Image Saliency and Contrast
Inconsistent illumination across imaging instruments poses significant challenges for accurate cell detection and analysis. Conventional methods (e.g., histogram equalization and basic filtering) struggle to adapt to complex lighting conditions, resulting in limited image enhancement and inconsistent performance. To address these issues, we propose the transformer-convolutional neural network (CNN) model with illumination adaptation (TCIA) model, which improves cell image saliency and contrast. By extracting illumination invariant features (IIF) using a locally sensitive histogram as prior knowledge, our model effectively adapts to varying illumination conditions. The TCIA framework employs hybrid convolution blocks (HCBs) to extract and preserve essential features from image pairs, followed by a two-branch decomposition-fusion network that separates features into low-frequency and high-frequency components. The Lite-Transformer (LT) captures global context for low-frequency features, while the circular difference invertible (CDI) module focuses on fine-grained textures and edges for high-frequency features. These features are then fused and reconstructed to produce high-contrast, salient images. Extensive experiments on three datasets (MoNuSeg, MoNuSAC, and our contributed MTGC) demonstrate that TCIA outperforms existing methods in image fusion and cell detection, achieving an average improvement in detection accuracy of 2%. This work provides a robust and innovative solution for enhanced cell imaging, contributing to more precise diagnostics and analysis. The source code will be available at https://github.com/Mrzhans/TCIA.
@article{yang2025tcia,title={TCIA: A Transformer-CNN Model With Illumination Adaptation for Enhancing Cell Image Saliency and Contrast},author={Yang, Jietao and Huang, Guoheng and Luo, Yanzhang and Zhang, Xiaofeng and Yuan, Xiaochen and Chen, Xuhang and Pun, Chi-Man and Cai, Mu-yan},year={2025},journal={IEEE Transactions on Instrumentation and Measurement},publisher={IEEE},volume={74},pages={1--15},doi={10.1109/TIM.2025.3527542},}
NiDNeXt: Cross-Channel Interactive And Multi-Scale Fusion for Nighttime Dehazing
Due to severe haze pollution and color attenuation, nighttime dehazing is an extremely challenging problem. Current research often neglects the impact of multiple unevenly illuminated active color light sources in night scenes, which may lead to halo, mist, glow and noise with localized, coupled, inconsistent frequency and unnatural characteristics. Additionally, after fog removal, night images may suffer from color distortion, detail loss, and texture blur. To address these issues, we present NiDNeXt, a nighttime dehazing network that integrates multi-scale progressive fusion (MSPF), cross-channel interactive attention (CCIA), and Fourier dynamic frequency filter (FDFF) modules. MSPF fuses spatial and frequency information locally, removing haze, glow, and noise in a coarse-to-fine manner across multiple scales while regenerating image details. CCIA allows channels to selectively absorb valuable information from adjacent channels using learned dynamic weights, enhancing the extraction of clear elements, color channel compensation, and texture restoration. FDFF, utilized within MSPF and CCIA, exploits dual-domain difference information to improve haze removal, glow elimination, texture restoration, and color correction. Our experiments on public benchmark datasets confirm the effectiveness and superiority of NiDNeXt over state-of-the-art methods. Our code will be made public at https://github.com/AQUAY16/NiDNeXt.
@article{lai2025nidnext,title={NiDNeXt: Cross-Channel Interactive And Multi-Scale Fusion for Nighttime Dehazing},author={Lai, Yuxuan and Huang, Guoheng and Cheng, Lianglun and Chen, Xuhang and Yuan, Xiaochen and Zhong, Guo and Pun, Chi-Man},year={2025},journal={Measurement Science and Technology},publisher={IOP Publishing},volume={36},number={7},pages={076111},doi={10.1088/1361-6501/adea8d},}
An asymmetric calibrated transformer network for underwater image restoration
Underwater image restoration remains challenging due to complex light propagation and scattering effects in aqueous environments. While recent transformer-based methods have shown promising results in image restoration tasks, they often struggle with the domain gap between underwater and air-captured images and lack explicit mechanisms to handle underwater-specific degradations. This paper presents AsymCT-UIR, a novel asymmetric calibrated transformer network specifically designed for underwater image restoration. Unlike conventional symmetric architectures, our model employs distinct processing pathways: an encoder with learnable calibration modules for underwater-to-air domain adaptation and a decoder with dual attention transformers for feature restoration. The asymmetric design enables effective distortion correction while preserving fine details through adaptive feature calibration and efficient attention mechanisms. Extensive experiments on benchmark datasets demonstrate that our AsymCT-UIR achieves superior performance compared to state-of-the-art methods. The proposed method shows robust performance across various underwater conditions and degradation types, making it practical for real-world applications.
@article{guo2025asymmetric,title={An asymmetric calibrated transformer network for underwater image restoration},author={Guo, Xiaojiao and Luo, Shenghong and Dong, Yihang and Liang, Zexiao and Li, Zimeng and Zhang, Xiujun and Chen, Xuhang},year={2025},journal={The Visual Computer},publisher={Springer},volume={41},number={9},pages={6465--6477},doi={10.1007/s00371-025-03947-0},}
ConnectomeDiffuser: Generative AI Enables Brain Network Construction From Diffusion Tensor Imaging
Brain network analysis plays a crucial role in diagnosing and monitoring neurodegenerative disorders such as Alzheimer’s disease (AD). Existing approaches for constructing structural brain networks from diffusion tensor imaging (DTI) often rely on specialized toolkits that suffer from inherent limitations: operator subjectivity, labor-intensive workflows, and restricted capacity to capture complex topological features and disease-specific biomarkers. To overcome these challenges and advance computational neuroimaging instrumentation, ConnectomeDiffuser is proposed as a novel diffusion-based framework for automated end-to-end brain network construction from DTI. The proposed model combines three key components: (1) a Template Network that extracts topological features from 3D DTI scans using Riemannian geometric principles, (2) a diffusion model that generates comprehensive brain networks with enhanced topological fidelity, and (3) a Graph Convolutional Network classifier that incorporates disease-specific markers to improve diagnostic accuracy. ConnectomeDiffuser demonstrates superior performance by capturing a broader range of structural connectivity and pathology-related information, enabling more sensitive analysis of individual variations in brain networks. Experimental validation on datasets representing two distinct neurodegenerative conditions demonstrates significant performance improvements over other brain network methods. This work contributes to the advancement of instrumentation in the context of neurological disorders, providing clinicians and researchers with a robust, generalizable measurement framework that facilitates more accurate diagnosis, deeper mechanistic understanding, and improved therapeutic monitoring of neurodegenerative diseases such as AD.
@article{chen2025connectomediffuser,title={ConnectomeDiffuser: Generative AI Enables Brain Network Construction From Diffusion Tensor Imaging},author={Chen, Xuhang and Shen, Yanyan and Mahmud, Mufti and Kwok-Po Ng, Michael and Tsang, Kim-Fung and Wang, Shanshan and Pun, Chi-Man and Wang, Shuqiang},year={2025},journal={IEEE Transactions on Consumer Electronics},volume={71},number={3},pages={7835--7847},doi={10.1109/TCE.2025.3592925},}
Functional ultrasound (fUS) imaging provides exceptional spatiotemporal resolution for neurovascular mapping, yet its practical application is significantly hampered by critical challenges. Foremost among these is data scarcity, arising from ethical considerations and signal degradation through the cranium, which collectively limit dataset diversity and compromise the fairness of downstream machine learning models. To address these limitations, we introduce UltraVAR (Ultrasound Visual Auto-Regressive model), the first data augmentation framework designed for fUS imaging that leverages a pre-trained visual auto-regressive generative model. UltraVAR is designed not only to mitigate data scarcity but also to enhance model fairness through the reconstruction of diverse and physiologically plausible fUS samples. The generated samples preserve essential neurovascular coupling features—specifically, the dynamic interplay between neural activity and microvascular hemodynamics. This capability distinguishes UltraVAR from conventional augmentation techniques, which often disrupt these vital physiological correlations and consequently fail to improve, or even degrade, downstream task performance. The proposed UltraVAR employs a scale-by-scale reconstruction mechanism that meticulously preserves the spatial topological relationships within vascular networks. The framework’s fidelity is further enhanced by two integrated modules: the Smooth Scaling Layer, which ensures the preservation of critical image information during multi-scale feature propagation, and the Perception Enhancement Module, which actively suppresses artifact generation via a dynamic residual compensation mechanism. Comprehensive experimental validation demonstrates that datasets augmented with UltraVAR yield statistically significant improvements in downstream classification accuracy. This work establishes a robust foundation for advancing ultrasound-based neuromodulation techniques and brain-computer interface technologies by enabling the reconstruction of high-fidelity, diverse fUS data.
@article{chen2025high-fidelity,title={High-Fidelity Functional Ultrasound Reconstruction via a Visual Auto-Regressive Framework},author={Chen, Xuhang and Li, Zhuo and Shen, Yanyan and Mahmud, Mufti and Pham, Hieu and Ng, Michael Kwok-Po and Pun, Chi-Man and Wang, Shuqiang},year={2025},journal={IEEE Journal of Biomedical and Health Informatics},doi={10.1109/JBHI.2025.3623196},publisher={IEEE}}
2024
WavEnhancer: Unifying Wavelet and Transformer for Image Enhancement
Image enhancement is a widely used technique in digital image processing that aims to improve image aesthetics and visual quality. However, traditional methods of enhancement based on pixel-level or global-level modifications have limited effectiveness. Recently, as learning-based techniques gain popularity, various studies are now focusing on utilizing networks for image enhancement. However, these techniques often fail to optimize image frequency domains. This study addresses this gap by introducing a transformer-based model for improving images in the wavelet domain. The proposed model refines various frequency bands of an image and prioritizes local details and high-level features. Consequently, the proposed technique produces superior enhancement results. The proposed model’s performance was assessed through comprehensive benchmark evaluations, and the results suggest it outperforms the state-of-the-art techniques.
@article{li2024wavenhancer,title={WavEnhancer: Unifying Wavelet and Transformer for Image Enhancement},author={Li, Zinuo and Chen, Xuhang and Guo, Shuna and Wang, Shuqiang and Pun, Chi-Man},year={2024},journal={Journal of Computer Science and Technology},publisher={Springer},volume={39},number={2},pages={336--345},doi={10.1007/s11390-024-3414-z},}
U-shaped convolutional transformer GAN with multi-resolution consistency loss for restoring brain functional time-series and dementia diagnosis
Qiankun
Zuo
, Ruiheng
Li, Binghua
Shi, Jin
Hong, Yanfei
Zhu
, Xuhang
Chen, Yixian
Wu, and Jia
Guo†
The blood oxygen level-dependent (BOLD) signal derived from functional neuroimaging is commonly used in brain network analysis and dementia diagnosis. Missing the BOLD signal may lead to bad performance and misinterpretation of findings when analyzing neurological disease. Few studies have focused on the restoration of brain functional time-series data.
@article{zuo2024u-shaped,title={U-shaped convolutional transformer GAN with multi-resolution consistency loss for restoring brain functional time-series and dementia diagnosis},author={Zuo, Qiankun and Li, Ruiheng and Shi, Binghua and Hong, Jin and Zhu, Yanfei and Chen, Xuhang and Wu, Yixian and Guo, Jia},year={2024},journal={Frontiers in Computational Neuroscience},publisher={Frontiers Media SA},volume={18},pages={1387004},doi={10.3389/fncom.2024.1387004},}
RM-UNet: UNet-like Mamba with rotational SSM module for medical image segmentation
Accurate segmentation of tissues and lesions is crucial for disease diagnosis, treatment planning, and surgical navigation. Yet, the complexity of medical images presents significant challenges for traditional Convolutional Neural Networks and Transformer models due to their limited receptive fields or high computational complexity. State Space Models (SSMs) have recently shown notable vision performance, particularly Mamba and its variants. However, their feature extraction methods may not be sufficiently effective and retain some redundant structures, leaving room for parameter reduction. In response to these challenges, we introduce a methodology called Rotational Mamba-UNet, characterized by Residual Visual State Space (ResVSS) block and Rotational SSM Module. The ResVSS block is devised to mitigate network degradation caused by the diminishing efficacy of information transfer from shallower to deeper layers. Meanwhile, the Rotational SSM Module is devised to tackle the challenges associated with channel feature extraction within State Space Models. Finally, we propose a weighted multi-level loss function, which fully leverages the outputs of the decoder’s three stages for supervision. We conducted experiments on ISIC17, ISIC18, CVC-300, Kvasir-SEG, CVC-ColonDB, Kvasir-Instrument datasets, and Low-grade Squamous Intraepithelial Lesion datasets provided by The Third Affiliated Hospital of Sun Yat-sen University, demonstrating the superior segmentation performance of our proposed RM-UNet. Additionally, compared to the previous VM-UNet, our model achieves a one-third reduction in parameters. Our code is available at https://github.com/Halo2Tang/RM-UNet.
@article{tang2024rm-unet,title={RM-UNet: UNet-like Mamba with rotational SSM module for medical image segmentation},author={Tang, Hao and Huang, Guoheng and Cheng, Lianglun and Yuan, Xiaochen and Tao, Qi and Chen, Xuhang and Zhong, Guo and Yang, Xiaohui},year={2024},journal={Signal, Image and Video Processing},publisher={Springer},volume={18},number={11},pages={8427--8443},doi={10.1007/s11760-024-03484-8},}
Cross-domain visual prompting with spatial proximity knowledge distillation for histological image classification
Xiaohong
Li, Guoheng
Huang†, Lianglun
Cheng, Guo
Zhong†, Weihuang
Liu
, Xuhang
Chen, and Muyan
Cai†
Histological classification is a challenging task due to the diverse appearances, unpredictable variations, and blurry edges of histological tissues. Recently, many approaches based on large networks have achieved satisfactory performance. However, most of these methods rely heavily on substantial computational resources and large high-quality datasets, limiting their practical application. Knowledge Distillation (KD) offers a promising solution by enabling smaller networks to achieve performance comparable to that of larger networks. Nonetheless, KD is hindered by the problem of high-dimensional characteristics, which makes it difficult to capture tiny scattered features and often leads to the loss of edge feature relationships.
@article{li2024cross-domain,title={Cross-domain visual prompting with spatial proximity knowledge distillation for histological image classification},author={Li, Xiaohong and Huang, Guoheng and Cheng, Lianglun and Zhong, Guo and Liu, Weihuang and Chen, Xuhang and Cai, Muyan},year={2024},journal={Journal of Biomedical Informatics},publisher={Elsevier},volume={158},pages={104728},doi={10.1016/j.jbi.2024.104728},}
MFDNet: Multi-Frequency Deflare Network for efficient nighttime flare removal
When light is scattered or reflected accidentally in the lens, flare artifacts may appear in the captured photographs, affecting the photographs’ visual quality. The main challenge in flare removal is to eliminate various flare artifacts while preserving the original content of the image. To address this challenge, we propose a lightweight Multi-Frequency Deflare Network (MFDNet) based on the Laplacian Pyramid. Our network decomposes the flare-corrupted image into low- and high-frequency bands, effectively separating the illumination and content information in the image. The low-frequency part typically contains illumination information, while the high-frequency part contains detailed content information. So our MFDNet consists of two main modules: the Low-Frequency Flare Perception Module (LFFPM) to remove flare in the low-frequency part and the Hierarchical Fusion Reconstruction Module (HFRM) to reconstruct the flare-free image. Specifically, to perceive flare from a global perspective while retaining detailed information for image restoration, LFFPM utilizes Transformer to extract global information while utilizing a convolutional neural network to capture detailed local features. Then HFRM gradually fuses the outputs of LFFPM with the high-frequency component of the image through feature aggregation. Moreover, our MFDNet can reduce the computational cost by processing in multiple frequency bands instead of directly removing the flare on the input image. Experimental results demonstrate that our approach outperforms state-of-the-art methods in removing nighttime flare on real-world and synthetic images from the Flare7K dataset. Furthermore, the computational complexity of our model is remarkably low.
@article{jiang2024mfdnet,title={MFDNet: Multi-Frequency Deflare Network for efficient nighttime flare removal},author={Jiang, Yiguo and Chen, Xuhang and Pun, Chi-Man and Wang, Shuqiang and Feng, Wei},year={2024},journal={The Visual Computer},publisher={Springer},volume={40},number={11},pages={7575--7588},doi={10.1007/S00371-024-03540-X},}
2023
Generative AI for brain image computing and brain network computing: a review
Recent years have witnessed a significant advancement in brain imaging techniques that offer a non-invasive approach to mapping the structure and function of the brain. Concurrently, generative artificial intelligence (AI) has experienced substantial growth, involving using existing data to create new content with a similar underlying pattern to real-world data. The integration of these two domains, generative AI in neuroimaging, presents a promising avenue for exploring various fields of brain imaging and brain network computing, particularly in the areas of extracting spatiotemporal brain features and reconstructing the topological connectivity of brain networks. Therefore, this study reviewed the advanced models, tasks, challenges, and prospects of brain imaging and brain network computing techniques and intends to provide a comprehensive picture of current generative AI techniques in brain imaging. This review is focused on novel methodological approaches and applications of related new methods. It discussed fundamental theories and algorithms of four classic generative models and provided a systematic survey and categorization of tasks, including co-registration, super-resolution, enhancement, classification, segmentation, cross-modality, brain network analysis, and brain decoding. This paper also highlighted the challenges and future directions of the latest work with the expectation that future research can be beneficial.
@article{gong2023generative,title={Generative AI for brain image computing and brain network computing: a review},author={Gong, Changwei and Jing, Changhong and Chen, Xuhang and Pun, Chi-Man and Huang, Guoli and Saha, Ashirbani and Nieuwoudt, Martin and Li, Hanxiong and Hu, Yong and Wang, Shuqiang},year={2023},journal={Frontiers in Neuroscience},publisher={Frontiers Media SA},volume={17},pages={1203104},doi={10.3389/fnins.2023.1203104},}
Brain Functional Network Generation Using Distribution-Regularized Adversarial Graph Autoencoder with Transformer for Dementia Diagnosis
Qiankun
Zuo
, Junhua
Hu
, Yudong
Zhang†, Junren
Pan, Changhong
Jing
, Xuhang
Chen, Xiaobo
Meng, and Jin
Hong†
Computer Modeling in Engineering & Sciences: CMES, 2023
The topological connectivity information derived from the brain functional network can bring new insights for diagnosing and analyzing dementia disorders. The brain functional network is suitable to bridge the correlation between abnormal connectivities and dementia disorders. However, it is challenging to access considerable amounts of brain functional network data, which hinders the widespread application of data-driven models in dementia diagnosis. In this study, a novel distribution-regularized adversarial graph auto-Encoder (DAGAE) with transformer is proposed to generate new fake brain functional networks to augment the brain functional network dataset, improving the dementia diagnosis accuracy of data-driven models. Specifically, the label distribution is estimated to regularize the latent space learned by the graph encoder, which can make the learning process stable and the learned representation robust. Also, the transformer generator is devised to map the node representations into node-to-node connections by exploring the long-term dependence of highly-correlated distant brain regions. The typical topological properties and discriminative features can be preserved entirely. Furthermore, the generated brain functional networks improve the prediction performance using different classifiers, which can be applied to analyze other cognitive diseases. Attempts on the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset demonstrate that the proposed model can generate good brain functional networks. The classification results show adding generated data can achieve the best accuracy value of 85.33%, sensitivity value of 84.00%, specificity value of 86.67%. The proposed model also achieves superior performance compared with other related augmented models. Overall, the proposed model effectively improves cognitive disease diagnosis by generating diverse brain functional networks.
@article{zuo2023brain,title={Brain Functional Network Generation Using Distribution-Regularized Adversarial Graph Autoencoder with Transformer for Dementia Diagnosis},author={Zuo, Qiankun and Hu, Junhua and Zhang, Yudong and Pan, Junren and Jing, Changhong and Chen, Xuhang and Meng, Xiaobo and Hong, Jin},year={2023},journal={Computer Modeling in Engineering \& Sciences: CMES},publisher={Europe PMC Funders},volume={137},number={3},pages={2129--2147},doi={10.32604/cmes.2023.028732},}