Previously, I obtained my Ph.D. degree in Computer Science at University of Macau (UM) and the Shenzhen Institutes of Advanced Technology (SIAT), Chinese Academy of Sciences, under the supervision of Prof. Chi-Man Pun and Prof. Shuqiang Wang in 2025. Before that, I received the M.Eng. degree in Electrical Engineering and the M.Sc. degree in Computer and Information Technology from the University of Pennsylvania (UPenn), Philadelphia, USA, in 2019, and the B.Sc. degree in Electronic Information Science and Technology from the Sun Yat-Sen University (SYSU), Guangzhou, China, in 2016 and B.Eng. degree in Electronic Engineering from the Chinese University of Hong Kong (CUHK), Hong Kong, China, in 2016.
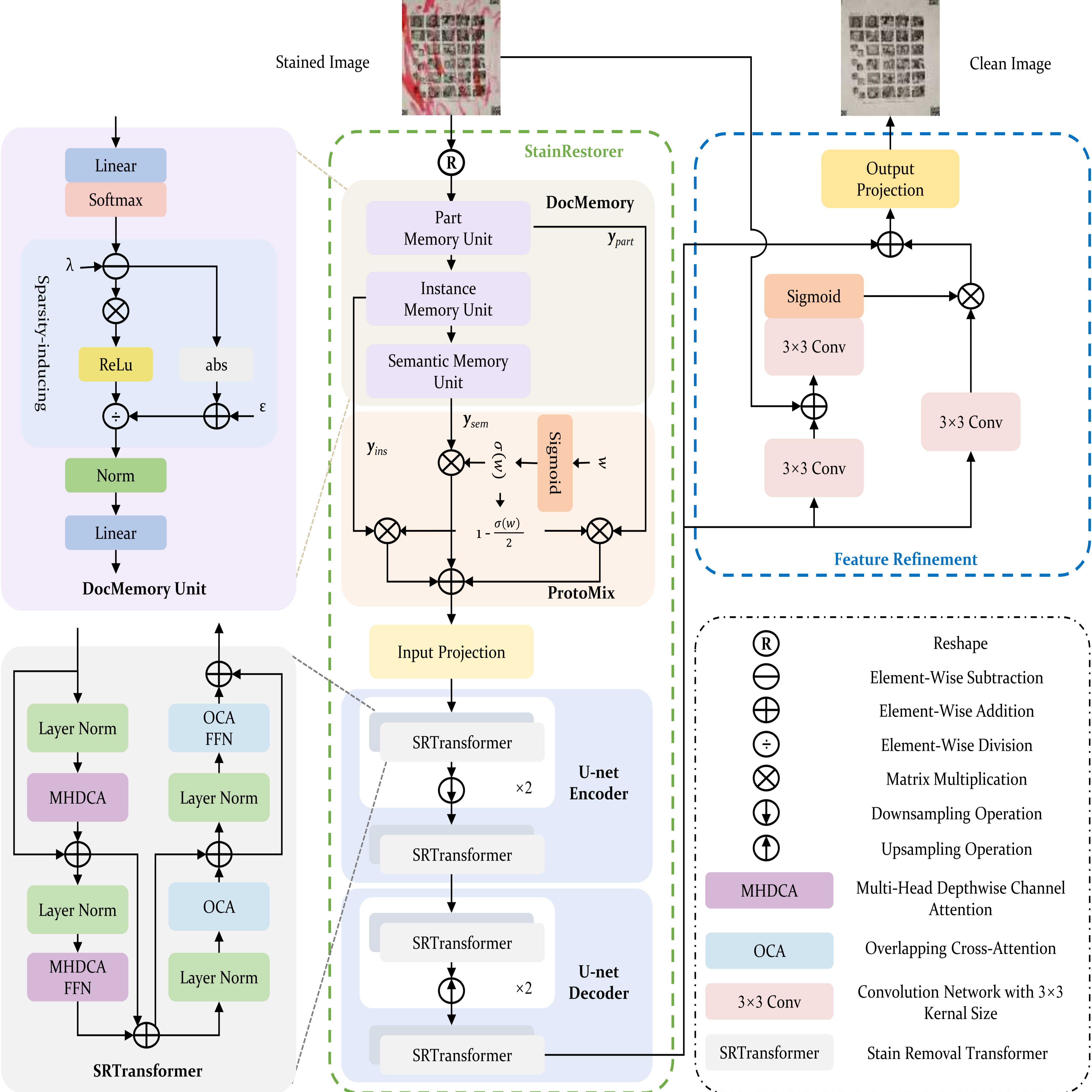
Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution (2145\times2245) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer’s superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc_Mark and StainDoc_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
@inproceedings{li2025high-fidelity,title={High-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer},author={Li, Mingxian and Sun, Hao and Lei, Yingtie and Zhang, Xiaofeng and Dong, Yihang and Zhou, Yilin and Li, Zimeng and Chen, Xuhang},year={2025},booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},publisher={IEEE},address={Tucson, AZ, USA},pages={7614--7624},doi={10.1109/WACV61041.2025.00740},}
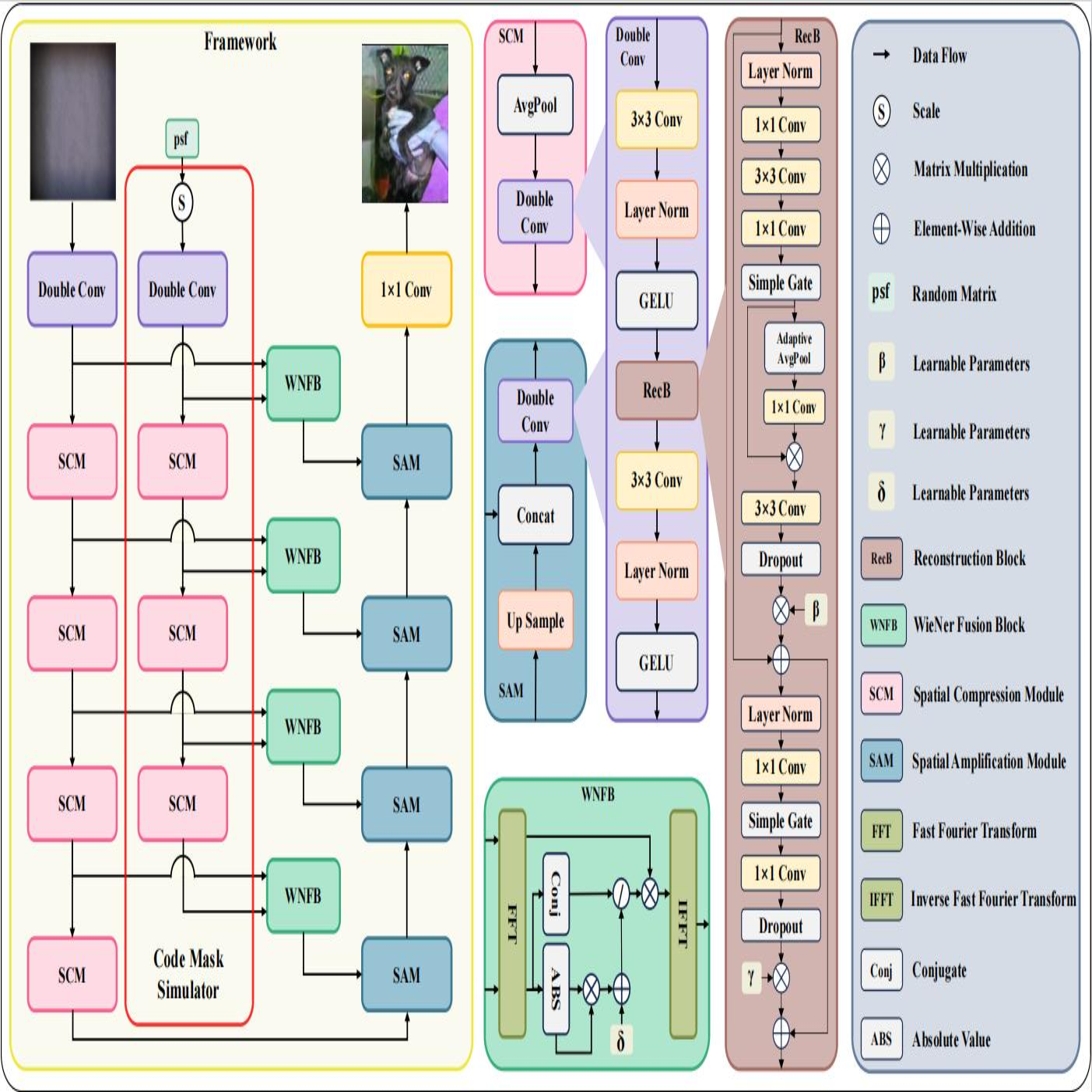
Lensless imaging stands out as a promising alternative to conventional lens-based systems, particularly in scenarios demanding ultracompact form factors and cost-effective architectures. However, such systems are fundamentally governed by the Point Spread Function (PSF), which dictates how a point source contributes to the final captured signal. Traditional lensless techniques often require explicit calibrations and extensive pre-processing, relying on static or approximate PSF models. These rigid strategies can result in limited adaptability to real-world challenges, including noise, system imperfections, and dynamic scene variations, thus impeding high-fidelity reconstruction. In this paper, we propose LensNet, an end-to-end deep learning framework that integrates spatial-domain and frequency-domain representations in a unified pipeline. Central to our approach is a learnable Coded Mask Simulator (CMS) that enables dynamic, data-driven estimation of the PSF during training, effectively mitigating the shortcomings of fixed or sparsely calibrated kernels. By embedding a Wiener filtering component, LensNet refines global structure and restores fine-scale details, thus alleviating the dependency on multiple handcrafted pre-processing steps. Extensive experiments demonstrate LensNet’s robust performance and superior reconstruction quality compared to state-of-the-art methods, particularly in preserving high-frequency details and attenuating noise. The proposed framework establishes a novel convergence between physics-based modeling and data-driven learning, paving the way for more accurate, flexible, and practical lensless imaging solutions for applications ranging from miniature sensors to medical diagnostics. The link of code is https://github.com/baijiesong/Lensnet.
@inproceedings{bai2025lensnet,title={LensNet: An End-to-End Learning Framework for Empirical Point Spread Function Modeling and Lensless Imaging Reconstruction},author={Bai, Jiesong and Yin, Yuhao and Dong, Yihang and Zhang, Xiaofeng and Pun, Chi-Man and Chen, Xuhang},year={2025},booktitle={Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI)},publisher={International Joint Conferences on Artificial Intelligence Organization},address={Montreal, Canada},pages={684--692},doi={10.24963/ijcai.2025/77},}
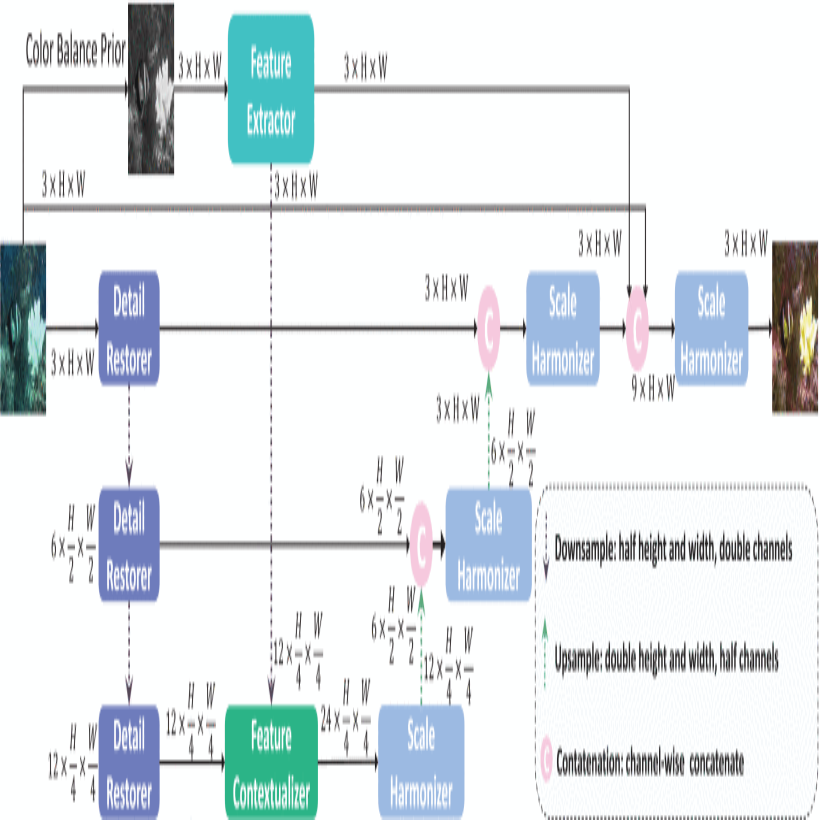
Underwater imaging grapples with challenges from light-water interactions, leading to color distortions and reduced clarity. In response to these challenges, we propose a novel Color Balance Prior Guided Hybrid Sense Underwater Image Restoration framework (GuidedHybSensUIR). This framework operates on multiple scales, employing the proposed Detail Restorer module to restore low-level detailed features at finer scales and utilizing the proposed Feature Contextualizer module to capture long-range contextual relations of high-level general features at a broader scale. The hybridization of these different scales of sensing results effectively addresses color casts and restores blurry details. In order to effectively point out the evolutionary direction for the model, we propose a novel Color Balance Prior as a strong guide in the feature contextualization step and as a weak guide in the final decoding phase. We construct a comprehensive benchmark using paired training data from three real-world underwater datasets and evaluate on six test sets, including three paired and three unpaired, sourced from four real-world underwater datasets. Subsequently, we tested 14 traditional and retrained 23 deep learning existing underwater image restoration methods on this benchmark, obtaining metric results for each approach. This effort aims to furnish a valuable benchmarking dataset for standard basis for comparison. The extensive experiment results demonstrate that our method outperforms 37 other state-of-the-art methods overall on various benchmark datasets and metrics, despite not achieving the best results in certain individual cases. The code and dataset are available at https://github.com/CXH-Research/GuidedHybSensUIR.
@article{guo2025underwater2,title={Underwater Image Restoration Through a Prior Guided Hybrid Sense Approach and Extensive Benchmark Analysis},author={Guo, Xiaojiao and Chen, Xuhang and Wang, Shuqiang and Pun, Chi-Man},year={2025},journal={IEEE Transactions on Circuits and Systems for Video Technology},publisher={IEEE},volume={35},number={5},pages={4784--4800},doi={10.1109/TCSVT.2025.3525593},}