Shadocnet: Learning Spatial-Aware Tokens in Transformer for Document Shadow Removal
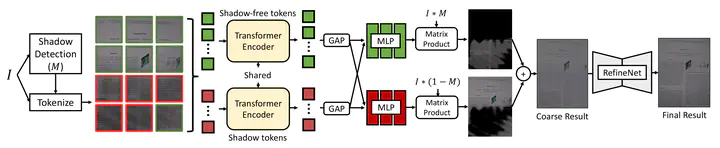 Model Architecture
Model ArchitectureAbstract
Shadow removal improves the visual quality and legibility of digital copies of documents. However, document shadow removal remains an unresolved subject. Traditional techniques rely on heuristics that vary from situation to situation. Given the quality and quantity of current public datasets, the majority of neural network models are ill-equipped for this task. In this paper, we propose a Transformer-based model for document shadow removal that utilizes shadow context encoding and decoding in both shadow and shadow-free regions. Additionally, shadow detection and pixel-level enhancement are included in the whole coarse-to-fine process. On the basis of comprehensive benchmark evaluations, it is competitive with state-of-the-art methods.
Type
Publication
IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL PROCESSING, 2023 [CCF-B]