 Model Architecture
Model ArchitectureAbstract
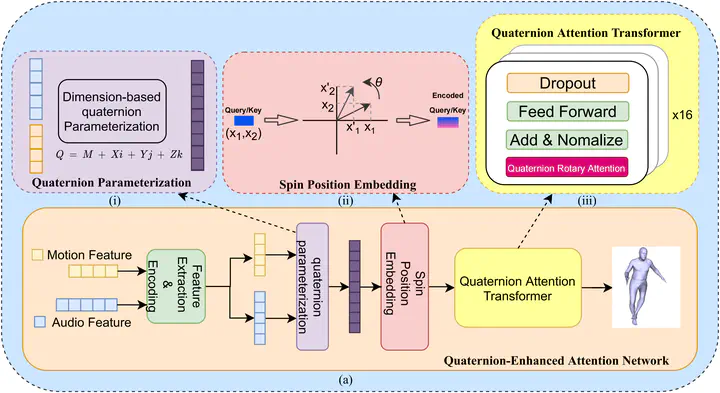
The study of music-generated dance is a novel and challenging Image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a Quaternion-Enhanced Attention Network (QEAN) for visual dance synthesis from a quaternion perspective, which consists of a Spin Position Embedding (SPE) module and a Quaternion Rotary Attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences, and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset respectively.