Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition
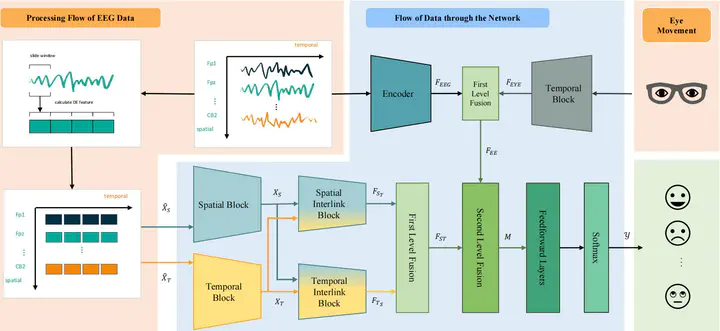 Model Architecture
Model ArchitectureAbstract
Emotion recognition based on Electroencephalography (EEG) has gained significant attention and diversified development in fields such as neural signal processing and affective computing. However, the unique brain anatomy of individuals leads to non-negligible natural differences in EEG signals across subjects, posing challenges for cross-subject emotion recognition. While recent studies have attempted to address these issues, they still face limitations in practical effectiveness and model framework unity. Current methods often struggle to capture the complex spatial-temporal dynamics of EEG signals and fail to effectively integrate multimodal information, resulting in suboptimal performance and limited generalizability across subjects. To overcome these limitations, we develop a Pre-trained model based Multimodal Mood Reader for cross-subject emotion recognition that utilizes masked brain signal modeling and interlinked spatial-temporal attention mechanism. The model learns universal latent representations of EEG signals through pre-training on large scale dataset, and employs Interlinked spatial-temporal attention mechanism to process Differential Entropy(DE) features extracted from EEG data. Subsequently, a multi-level fusion layer is proposed to integrate the discriminative features, maximizing the advantages of features across different dimensions and modalities. Extensive experiments on public datasets demonstrate Mood Reader’s superior performance in cross-subject emotion recognition tasks, outperforming state-of-the-art methods. Additionally, the model is dissected from attention perspective, providing qualitative analysis of emotion-related brain areas, offering valuable insights for affective research in neural signal processing.