FOPS-V: Feature-Aware Optimization and Parallel Scale Fusion for 3D Human Reconstruction in Video
 Model Architecture
Model ArchitectureAbstract
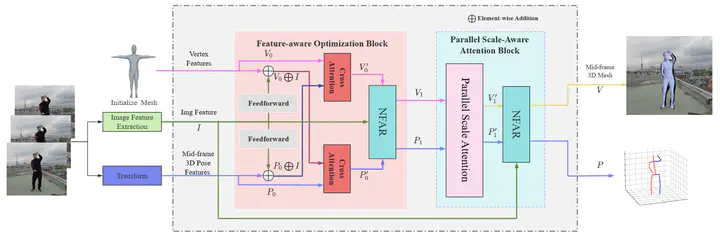
Video-based 3D human reconstruction, a fundamental task in computer vision, aims to accurately estimate the 3D pose and shape of the human body from video sequences. While recent methods leverage spatial and temporal feature extraction techniques, many remain limited by single-scale processing, hindering their performance in complex scenes. Additionally, challenges such as occlusion and complex poses often lead to inaccurate reconstructions. To address these limitations, we propose FOPS-V: Feature-aware Optimization and Parallel Scale Fusion for 3D Human Reconstruction in Video. Our approach comprises three key components: a Feature-Aware Optimization (FAO) block, a Parallel Scale-Aware Attention (PSAA) block, and a Normalized Feature-Aware Representation (NFAR) guided by Feature-Response Layer Normalization (FRLN). The FAO block enhances feature extraction by optimizing joint and mesh vertex representations through the fusion of image features and learned query vectors. The PSAA block performs subscale feature extraction for joint and mesh vertices and fuses multiscale feature information to improve pose and shape representations. Guided by FRLN, the NFAR addresses instability caused by variations in feature statistics within the FAO and PSAA blocks. This normalization, with an adaptable threshold, enhances robustness to noisy or outlier data, preventing performance degradation. Extensive evaluations on the 3DPW, MPI-INF-3DHP, and Human3.6M datasets demonstrate that FOPS-V outperforms state-of-the-art methods, highlighting its effectiveness for 3D human reconstruction in video.