Devignet: High-Resolution Vignetting Removal via a Dual Aggregated Fusion Transformer With Adaptive Channel Expansion
 Model Architecture
Model ArchitectureAbstract
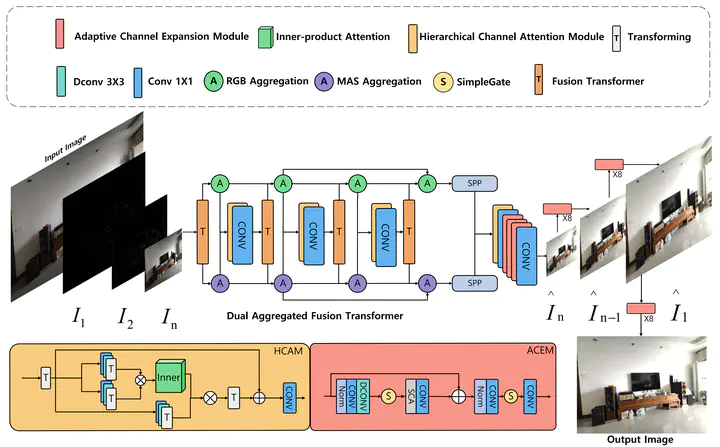
Vignetting commonly occurs as a degradation in images resulting from factors such as lens design, improper lens hood usage, and limitations in camera sensors. This degradation affects image details, color accuracy, and presents challenges in computational photography. Existing vignetting removal algorithms predominantly rely on ideal physics assumptions and hand-crafted parameters, resulting in ineffective removal of irregular vignetting and suboptimal results. Moreover, the substantial lack of real-world vignetting datasets hinders the objective and comprehensive evaluation of vignetting removal. To address these challenges, we present Vigset, a pioneering dataset for vignette removal. Vigset includes 983 pairs of both vignetting and vignetting-free high-resolution (5340×3697) real-world images under various conditions. In addition, We introduce DeVigNet, a novel frequency-aware Transformer architecture designed for vignetting removal. Through the Laplacian Pyramid decomposition, we propose the Dual Aggregated Fusion Transformer to handle global features and remove vignetting in the low-frequency domain. Additionally, we introduce the Adaptive Channel Expansion Module to enhance details in the high-frequency domain. The experiments demonstrate that the proposed model outperforms existing state-of-the-art methods. The code, models, and dataset are available at here.